We will now prove Talagrand’s majorizing measures theorem, showing that the generic chaining bound is tight for Gaussian processes. The proof here will be a bit more long-winded than the proof from Talagrand’s book, but also (I think), a bit more accessible as well. Most importantly, we will highlight the key idea with a simple combinatorial argument.
Theorem 1 Let be a Gaussian process, and let be a sequence of subsets such that and for . Then,
In order to make things slightly easier to work with, we look at an essentially equivalent way to state (1). Consider a Gaussian process and a sequence of increasing partitions of , where increasing means that is a refinement of for . Say that such a sequence is admissible if and for all . Also, for a partition and a point , we will use the notation for the unique set in which contains .
By choosing to be any set of points with one element in each piece of the partition , (1) yields,
We can now state our main theorem, which shows that this is essentially the only way to bound .
Theorem 2 There is a constant such that for any Gaussian process , there exists an admissible sequence which satisfies,
Theorem 3 For some constants and , the following holds. Suppose is a Gaussian process, and let be such that for . Then,
We will use only Theorem 3 and the fact that whenever to prove Theorem 2 (so, in fact, Theorem 2 holds with replaced by more general functionals satisfying an inequality like (4)).
The partitioning scheme
First, we will specify the partitioning scheme to form an admissible sequence , and then we will move on to its analysis. As discussed in earlier posts, we may assume that is finite. Every set will have a value associated with it, such that is always an upper bound on the radius of the set , i.e. there exists a point such that .
Initially, we set and . Now, we assume that we have constructed , and show how to form the partition . To do this, we will break every set into at most pieces. This will ensure that
Let be the constant from Theorem 3. Put , and let . We partition into pieces as follows. First, choose which maximizes the value
Then, set . We put .
A remark: The whole idea here is that we have chosen the “largest possible piece,” (in terms of -value), but we have done this with respect to the ball, while we cut out the ball. The reason for this will not become completely clear until the analysis, but we can offer a short explanation here. Looking at the lower bound (4), observe that the balls are disjoint under the assumptions, but we only get “credit” for the balls. When we apply this lower bound, it seems that we are throwing a lot of the space away. At some point, we will have to make sure that this thrown away part doesn’t have all the interesting stuff! The reason for our choice of vs. is essentially this: We want to guarantee that if we miss the interesting stuff at this level, then the previous level took care of it. To have this be the case, we will have to look forward (a level down), which (sort of) explains our choice of optimizing for the ball.
Now we continue in this fashion. Let be the remaining space after we have cut out pieces. For , choose to maximize the value
For , set , and put .
So far, we have been chopping the space into smaller pieces. If for some , we have finished our construction of . But maybe we have already chopped out pieces, and still some remains. In that case, we put , i.e. we throw everything else into . Since we cannot reduce our estimate on the radius, we also put .
We continue this process until is exhausted, i.e. eventually for some large enough, only contains singletons. This completes our description of the partitioning.
The tree
For the analysis, it will help to consider our partitioning process as having constructed a tree (in the most natural way). The root of the the tree is the set , and its children are the sets of , and so on. Let’s call this tree . It will help to draw and describe in a specific way. First, we will assign values to the edges of the tree. If and is a child of (i.e., and ), then the edge is given value:
If we define the value of a root-leaf path in as the sum of the edge lengths on that path, then for any ,
simply using .
Thus in order to prove Theorem 2, which states that for some ,
it will suffice to show that for some (other) constant , for any root-leaf path in , we have
Before doing this, we will fix a convention for drawing parts of . If a node has children , we will draw them from left to right. We will call an edge a right turn and every other edge will be referred to as a left turn. Note that some node may not have any right turn coming out of it (if the partitioning finished before the last step). Also, observe that along a left turn, the radius always drops by a factor of , while along a right turn, it remains the same.
We now make two observations about computing the value up to a universal constant.
Observation (1): In computing the value of a root-leaf path , we only need to consider right turns.
To see this, suppose that we have a right turn followed by a consecutive sequence of left turns. If the value of the right turn is , then the value of the following sequence of left turns is, in total, at most
In other words, because the radius decreases by a factor of along every left turn, their values decrease geometrically, making the whole sum comparable to the preceding right turn. (Recall that , so indeed the sum is geometric.)
If the problem of possibly of having no right turn in the path bothers you, note that we could artificially add an initial right turn into the root with value . This is justified since always holds. A different way of saying this is that if the path really contained no right turn, then its value is , and we can easily prove (6).
Observation (2): In computing the value of a root-leaf path , we need only consider the last right turn in any consecutive sequence of right turns.
Consider a sequence of consecutive right turns, and the fact that the radius does not decrease. The values (taking away the factor) look like . In other words, they are geometrically increasing, and thus using only the last right turn in every sequence, we only lose a constant factor.
We will abbreviate last right turn to LRT, and write to denote the value of , just counting last right turns. By the two observations, to show (6) (and hence finish the proof), it suffices to show that, for every root-leaf path in ,
The analysis
Recall that our tree has values on the edges, defined in (5). We will also put some natural values on the nodes. For a node (which, recall, is just a subset ), we put . So the edges have values and the nodes have values. Thus given any subset of nodes and edges in , we can talk about the value of the subset, which will be the sum of the values of the objects it contains. We will prove (7) by a sequence of inequalities on subsets.
Fix a root-leaf path , for which we will prove (7). Let’s prove the fundamental inequality now. We will consider two consecutive LRTs along . (If there is only one LRT in , then we are done by the preceding remarks.) See the figure below. The dashed lines represent a (possibly empty) sequence of left turns and then right turns. The two LRTs are marked.
We will prove the following inequality, which is the heart of the proof. One should understand that the inequality is on the values of the subsets marked in red. The first subset contains two nodes, and the second contains two nodes and an edge.
Figure A.
With this inequality proved, the proof is complete. Let’s see why. We start with the first LRT. Since for any node in , we have the inequality:
This gets us started. Now we apply the inequality of Figure A repeatedly to each pair of consecutive LRTs in the path . What do we have when we’ve exhausted the path ? Well, precisely all the LRTs in are marked, yielding , as desired.
The LRT inequality
Now we are left to prove the inequality in Figure A. First, let’s label some of the nodes. Let , and suppose that . The purple values are not the radii of the corresponding nodes, but they are upper bounds on the radii, recalling that along every left turn, the radius decreases by a factor of . Since there are at least two left turns in the picture, we get a upper bound on the radius of .
Part of the inequality is easy: We have since . So we can transfer the red mark from to . We are thus left to prove that
This will allow us to transfer the red mark from to the LRT coming out of and to .
When was partitioned into pieces, this was by our greedy partitioning algorithm using centers . Since we cut out the ball around each center, we have for all . Applying the Sudakov inequality (Theorem 3), we have
where the last line follows from the greedy manner in which the ‘s were chosen.
But now we claim that
This follows from two facts. First, (since actually). Secondly, the radius of is at most ! But was chosen to maximize the value of over all balls of radius , so in particular its -value is at least that of the ball containing .
Combining (9) and the preceding inequality, we prove (8), and thus that the inequality of Figure A is valid. This completes the proof.
be a Gaussian process, and let
be a sequence of subsets such that
and
for
. Then,
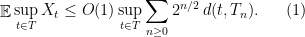
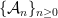

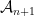
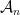




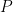
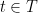


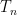

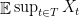
such that for any Gaussian process
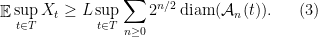
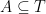
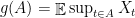
and
, the following holds. Suppose
be such that
for
. Then,



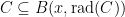

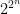


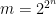


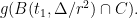

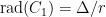
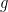





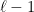
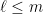
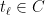




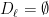
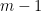

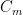

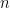

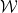
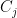
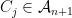

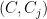



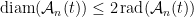

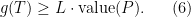
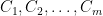
















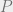
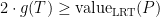


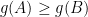
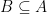
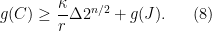


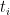



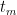


Great posts! (I am also curious what image I will get)
Thanks Gil. I can’t put my finger on it, but I feel there is a slight resemblance… maybe it’s the glasses.
Why is this called “majorizing” measures?