In preparation for the next post on entropy optimality, we need a little background on lifts of polytopes and non-negative matrix factorization.
1.1. Polytopes and inequalities
A 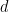 -dimensional convex polytope
-dimensional convex polytope  is the convex hull of a finite set of points in
is the convex hull of a finite set of points in 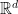 . Equivalently, it is a compact set defined by a family of linear inequalities
. Equivalently, it is a compact set defined by a family of linear inequalities
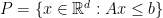
for some matrix  .
.
Let us give a measure of complexity for 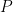 : Define
: Define  to be the smallest number
to be the smallest number 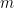 such that for some
such that for some  , we have
, we have
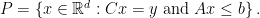
In other words, this is the minimum number of inequalities needed to describe . If is full-dimensional, then this is precisely the number of facets of (a facet is a maximal proper face of ).
Thinking of as a measure of complexity makes sense from the point of view of optimization: Interior point methods can efficiently optimize linear functions over (to arbitrary accuracy) in time that is polynomial in .
1.2. Lifts of polytopes
Many simple polytopes require a large number of inequalities to describe. For instance, the cross-polytope

has 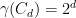 . On the other hand,
. On the other hand,  is the projection of the polytope
is the projection of the polytope

onto the  coordinates, and manifestly,
coordinates, and manifestly,  . Thus is the (linear) shadow of a much simpler polytope in a higher dimension.
. Thus is the (linear) shadow of a much simpler polytope in a higher dimension.

[image credit: Fiorini, Rothvoss, and Tiwary]
A polytope  is called a lift of the polytope if is the image of under a linear projection. Again, from an optimization stand point, lifts are important: If we can optimize linear functionals over , then we can optimize linear functionals over . Define now
is called a lift of the polytope if is the image of under a linear projection. Again, from an optimization stand point, lifts are important: If we can optimize linear functionals over , then we can optimize linear functionals over . Define now 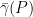 to be the minimal value of
to be the minimal value of 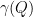 over all lifts of . (The value is sometimes called the (linear) extension complexity of .)
over all lifts of . (The value is sometimes called the (linear) extension complexity of .)
1.3. The permutahedron

Here is a somewhat more interesting family of examples where lifts reduce complexity. The permutahedron  is the convex hull of the vectors
is the convex hull of the vectors  where
where 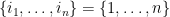 . It is known that
. It is known that 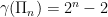 .
.
Let  denote the convex hull of the
denote the convex hull of the  permutation matrices. The Birkhoff-von Neumann theorem tells us that
permutation matrices. The Birkhoff-von Neumann theorem tells us that 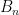 is precisely the set of doubly stochastic matrices, thus
is precisely the set of doubly stochastic matrices, thus  (corresponding to the non-negativity constraints on each entry).
(corresponding to the non-negativity constraints on each entry).
Observe that  is the linear image of under the map
is the linear image of under the map  , i.e. we multiply a matrix
, i.e. we multiply a matrix  on the right by the column vector
on the right by the column vector  . Thus is a lift of , and we conclude that
. Thus is a lift of , and we conclude that  .
.
1.4. The cut polytope
If 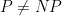 , there are certain combinatorial polytopes we should not be able to optimize over efficiently. A central example is the cut polytope:
, there are certain combinatorial polytopes we should not be able to optimize over efficiently. A central example is the cut polytope:  is the convex hull of all matrices of the form
is the convex hull of all matrices of the form  for some subset
for some subset  . Here,
. Here, 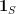 denotes the characteristic function of
denotes the characteristic function of 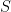 .
.
Note that the MAX-CUT problem on a graph 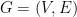 can be encoded in the following way: Let
can be encoded in the following way: Let 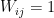 if
if  and
and 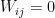 otherwise. Then the value of the maximum cut in
otherwise. Then the value of the maximum cut in 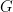 is precisely the maximum of
is precisely the maximum of  for
for  . Accordingly, we should expect that
. Accordingly, we should expect that 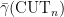 cannot be bounded by any polynomial in
cannot be bounded by any polynomial in 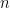 (lest we violate a basic tenet of complexity theory).
(lest we violate a basic tenet of complexity theory).
1.5. Non-negative matrix factorization
The key to understanding comes from Yannakakis’ factorization theorem.
Consider a polytope and let us write in two ways: As a convex hull of vertices
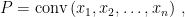
and as an intersection of half-spaces: For some and 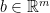 ,
,

Given this pair of representations, we can define the corresponding slack matrix of by
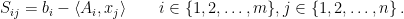
Here, 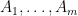 denote the rows of
denote the rows of 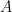 .
.
We need one more definition. In what follows, we will use 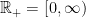 . If we have a non-negative matrix
. If we have a non-negative matrix  , then a rank-
, then a rank- non-negative factorization of
non-negative factorization of 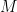 is a factorization
is a factorization 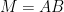 where
where  and
and 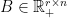 . We then define the non-negative rank of , written
. We then define the non-negative rank of , written 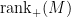 , to be the smallest such that admits a rank- non-negative factorization.
, to be the smallest such that admits a rank- non-negative factorization.
Theorem 1 (Yannakakis) For every polytope , it holds that  for any slack matrix of .
for any slack matrix of .
The key fact underlying this theorem is Farkas’ Lemma. It asserts that if  , then every valid linear inequality over can be written as a non-negative combination of the defining inequalities
, then every valid linear inequality over can be written as a non-negative combination of the defining inequalities  .
.
There is an interesting connection here to proof systems. The theorem says that we can interpret as the minimum number of axioms so that every valid linear inequality for can be proved using a conic (i.e., non-negative) combination of the axioms.
1.6. Slack matrices and the correlation polytope
Thus to prove a lower bound on , it suffices to find a valid set of linear inequalities for  and prove a lower bound on the non-negative rank of the corresponding slack matrix.
and prove a lower bound on the non-negative rank of the corresponding slack matrix.
Toward this end, consider the correlation polytope  given by
given by

It is an exercise to see that 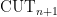 and
and  are linearly isomorphic.
are linearly isomorphic.
Now we identify a particularly interesting family of valid linear inequalities for . (In fact, it turns out that this will also be an exhaustive list.) A quadratic multi-linear function on  is a function
is a function 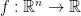 of the form
of the form

for some real numbers  and
and 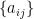 .
.
Suppose 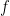 is a quadratic multi-linear function that is also non-negative on
is a quadratic multi-linear function that is also non-negative on  . Then “
. Then “ ” can be encoded as a valid linear inequality on . To see this, write
” can be encoded as a valid linear inequality on . To see this, write 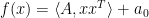 where
where  . (Note that
. (Note that  is intended to be the standard inner product on
is intended to be the standard inner product on  .)
.)
Now let  be the set of all quadratic multi-linear functions that are non-negative on , and consider the matrix (represented here as a function)
be the set of all quadratic multi-linear functions that are non-negative on , and consider the matrix (represented here as a function) 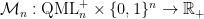 given by
given by

Then from the above discussion, 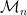 is a valid sub-matrix of some slack matrix of . To summarize, we have the following theorem.
is a valid sub-matrix of some slack matrix of . To summarize, we have the following theorem.
Theorem 2 For all 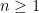 , it holds that
, it holds that  .
.
It is actually the case that  . The next post will focus on providing a lower bound on
. The next post will focus on providing a lower bound on 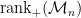 .
.
