Recall that our goal is to sketch a proof of the following theorem, where the notation is from the last post. I will assume a knowledge of the three posts on polyhedral lifts and non-negative rank, as our argument will proceed by analogy.
Theorem 1 For every  and
and 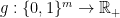 , there exists a constant
, there exists a constant  such that the following holds. For every
such that the following holds. For every 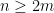 ,
,

where 
In this post, we will see how John’s theorem can be used to transform a psd factorization into one of a nicer analytic form. Using this, we will be able to construct a convex body that contains an approximation to every non-negative matrix of small psd rank.
1.1. Finite-dimensional operator norms
Let  denote a finite-dimensional Euclidean space over
denote a finite-dimensional Euclidean space over  equipped with inner product
equipped with inner product  and norm
and norm 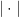 . For a linear operator
. For a linear operator  , we define the operator, trace, and Frobenius norms by
, we define the operator, trace, and Frobenius norms by

Let  denote the set of self-adjoint linear operators on . Note that for
denote the set of self-adjoint linear operators on . Note that for 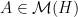 , the preceding three norms are precisely the
, the preceding three norms are precisely the 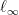 ,
,  , and
, and 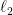 norms of the eigenvalues of
norms of the eigenvalues of 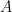 . For
. For  , we use
, we use  to denote that is positive semi-definite and
to denote that is positive semi-definite and  for
for  . We use
. We use  for the set of density operators: Those with and
for the set of density operators: Those with and 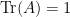 .
.
One should recall that  is an inner product on the space of linear operators, and we have the operator analogs of the Hölder inequalities:
is an inner product on the space of linear operators, and we have the operator analogs of the Hölder inequalities:  and
and 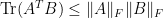 .
.
1.2. Rescaling the psd factorization
As in the case of non-negative rank, consider finite sets  and
and  and a matrix
and a matrix  . For the purposes of proving a lower bound on the psd rank of some matrix, we would like to have a nice analytic description.
. For the purposes of proving a lower bound on the psd rank of some matrix, we would like to have a nice analytic description.
To that end, suppose we have a rank- psd factorization
psd factorization

where 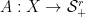 and
and  . The following result of Briët, Dadush and Pokutta (2013) gives us a way to “scale” the factorization so that it becomes nicer analytically. (The improved bound stated here is from an article of Fawzi, Gouveia, Parrilo, Robinson, and Thomas, and we follow their proof.)
. The following result of Briët, Dadush and Pokutta (2013) gives us a way to “scale” the factorization so that it becomes nicer analytically. (The improved bound stated here is from an article of Fawzi, Gouveia, Parrilo, Robinson, and Thomas, and we follow their proof.)
Lemma 2 Every 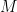 with
with  admits a factorization
admits a factorization  where
where 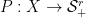 and
and  and, moreover,
and, moreover,

where  .
.
Proof: Start with a rank- psd factorization 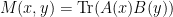 . Observe that there is a degree of freedom here, because for any invertible operator
. Observe that there is a degree of freedom here, because for any invertible operator  , we get another psd factorization
, we get another psd factorization  .
.
Let 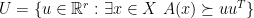 and
and  . Set
. Set 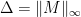 . We may assume that
. We may assume that  and
and 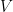 both span
both span 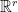 (else we can obtain a lower-rank psd factorization). Both sets are bounded by finiteness of and .
(else we can obtain a lower-rank psd factorization). Both sets are bounded by finiteness of and .
Let  and note that
and note that 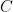 is centrally symmetric and contains the origin. Now John’s theorem tells us there exists a linear operator
is centrally symmetric and contains the origin. Now John’s theorem tells us there exists a linear operator  such that
such that
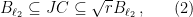
where 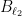 denotes the unit ball in the Euclidean norm. Let us now set
denotes the unit ball in the Euclidean norm. Let us now set  and
and  .
.
Eigenvalues of  : Let
: Let  be an eigenvector of normalized so the corresponding eigenvalue is
be an eigenvector of normalized so the corresponding eigenvalue is  . Then
. Then 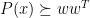 , implying that
, implying that  (here we use that
(here we use that  for any
for any  ). Since
). Since  , (2) implies that
, (2) implies that 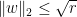 . We conclude that every eigenvalue of is at most .
. We conclude that every eigenvalue of is at most .
Eigenvalues of  : Let be an eigenvector of normalized so that the corresponding eigenvalue is . Then as before, we have
: Let be an eigenvector of normalized so that the corresponding eigenvalue is . Then as before, we have  and this implies
and this implies  . Now, on the one hand we have
. Now, on the one hand we have
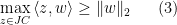
since  .
.
On the other hand:

Finally, observe that for any  and
and  , we have
, we have
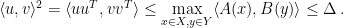
By convexity, this implies that  for all , bounding the right-hand side of (4) by
for all , bounding the right-hand side of (4) by  . Combining this with (3) yields
. Combining this with (3) yields 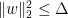 . We conclude that all the eigenvalues of are at most .
. We conclude that all the eigenvalues of are at most . 
1.3. Convex proxy for psd rank
Again, in analogy with the non-negative rank setting, we can define an “analytic psd rank” parameter for matrices  :
:

![\displaystyle \hphantom{xx} \mathop{\mathbb E}_{x \in X}[A(x)]=I,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chphantom%7Bxx%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bx+%5Cin+X%7D%5BA%28x%29%5D%3DI%2C++&bg=FFFFFF&fg=000000&s=0&c=20201002)
![\displaystyle \hphantom{xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx} \|B(y)\| \leq \frac{\alpha}{k}\, \mathop{\mathbb E}_{y \in Y}[\mathrm{Tr}(B(y))] \quad \forall y \in Y](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Chphantom%7Bxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx%7D+%5C%7CB%28y%29%5C%7C+%5Cleq+%5Cfrac%7B%5Calpha%7D%7Bk%7D%5C%2C+%5Cmathop%7B%5Cmathbb+E%7D_%7By+%5Cin+Y%7D%5B%5Cmathrm%7BTr%7D%28B%28y%29%29%5D+%5Cquad+%5Cforall+y+%5Cin+Y++&bg=FFFFFF&fg=000000&s=0&c=20201002)

Note that we have implicit equipped and with the uniform measure. The main point here is that  can be arbitrary. One can verify that
can be arbitrary. One can verify that  is convex.
is convex.
And there is a corresponding approximation lemma. We use 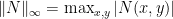 and
and 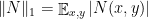 .
.
Lemma 3 For every non-negative matrix and every ![{\eta \in (0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Ceta+%5Cin+%280%2C1%5D%7D+&bg=FFFFFF&fg=000000&s=0&c=20201002) , there is a matrix
, there is a matrix 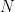 such that
such that 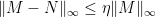 and
and

Using Lemma 2 in a straightforward way, it is not particularly difficult to construct the approximator . The condition ![{\mathop{\mathbb E}_x [A(x)] = I}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D_x+%5BA%28x%29%5D+%3D+I%7D+&bg=FFFFFF&fg=000000&s=0&c=20201002) poses a slight difficulty that requires adding a small multiple of the identity to the LHS of the factorization (to avoid a poor condition number), but this has a correspondingly small effect on the approximation quality. Putting “Alice” into “isotropic position” is not essential, but it makes the next part of the approach (quantum entropy optimization) somewhat simpler because one is always measuring relative entropy to the maximally mixed state.
poses a slight difficulty that requires adding a small multiple of the identity to the LHS of the factorization (to avoid a poor condition number), but this has a correspondingly small effect on the approximation quality. Putting “Alice” into “isotropic position” is not essential, but it makes the next part of the approach (quantum entropy optimization) somewhat simpler because one is always measuring relative entropy to the maximally mixed state.
