In the last post, we considered a Gaussian process  and were trying to find upper bounds on the quantity
and were trying to find upper bounds on the quantity  . We saw that one could hope to improve over the union bound by clustering the points and then taking mini union bounds in each cluster.
. We saw that one could hope to improve over the union bound by clustering the points and then taking mini union bounds in each cluster.
Hierarchical clustering
To specify a clustering, we’ll take a sequence of progressively finer approximations to our set  . First, recall that we fixed
. First, recall that we fixed  , and we have used the observation that
, and we have used the observation that  .
.
Now, assume that is finite. Write  , and consider a sequence of subsets
, and consider a sequence of subsets  such that
such that  . We will assume that for some large enough
. We will assume that for some large enough 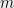 , we have
, we have  for
for  . For every
. For every  , let
, let  denote a “closest point map” which sends
denote a “closest point map” which sends  to the closest point in
to the closest point in  .
.
The main point is that we can now write, for any 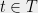 ,
,

This decomposition is where the term “chaining” arises, and now the idea is to bound the probability that  is large in terms of the segments in the chain.
is large in terms of the segments in the chain.
What should  look like?
look like?
One question that arises is how we should think about choosing the approximations . We are trading off two measures of quality: The denser is in the set (or, more precisely, in the set 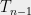 ) the smaller the variances of the segments
) the smaller the variances of the segments  will be. On the other hand, the larger is, the more segments we’ll have to take a union bound over.
will be. On the other hand, the larger is, the more segments we’ll have to take a union bound over.
So far, we haven’t used any property of our random variables except for the fact that they are centered. To make a more informed decision about how to choose the sets , let’s recall the classical Gaussian concentration bound.
Lemma 1 For every  and
and  ,
,
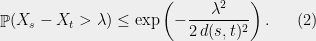
This should look familiar: 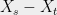 is a mean-zero Gaussian with variance
is a mean-zero Gaussian with variance  .
.
Now, a first instinct might be to choose the sets to be progressively denser in . In this case, a natural choice would be to insist on something like being a  -net in . If one continues down this path in the right way, a similar theory would develop. We’re going to take a different route and consider the other side of the tradeoff.
-net in . If one continues down this path in the right way, a similar theory would develop. We’re going to take a different route and consider the other side of the tradeoff.
Instead of insisting that has a certain level of accuracy, we’ll insist that is at most a certain size. Should we require 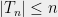 or
or  , or use some other function? To figure out the right bound, we look at (2). Suppose that
, or use some other function? To figure out the right bound, we look at (2). Suppose that 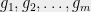 are i.i.d.
are i.i.d. 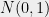 random variables. In that case, applying (2) and a union bound, we see that to achieve
random variables. In that case, applying (2) and a union bound, we see that to achieve

we need to select 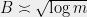 . If we look instead at
. If we look instead at 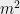 points instead of points, the bound grows to
points instead of points, the bound grows to 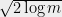 . Thus we can generally square the number of points before the union bound has to pay a constant factor increase. This suggests that the right scaling is something like
. Thus we can generally square the number of points before the union bound has to pay a constant factor increase. This suggests that the right scaling is something like 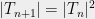 . So we’ll require that
. So we’ll require that  for all
for all  .
.
The generic chaining
This leads us to the generic chaining bound, due to Fernique (though the formulation we state here is from Talagrand).
Theorem 2 Let be a Gaussian process, and let  be a sequence of subsets such that
be a sequence of subsets such that  and
and  for . Then,
for . Then,
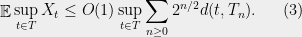
Proof: As before, let denote the closest point map and let . Using (2), for any , , and  , we have
, we have
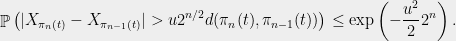
Now, the number of pairs 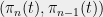 can be bounded by
can be bounded by  , so we have
, so we have
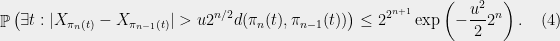
If we define the event
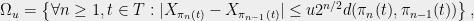
then summing (4) yields,
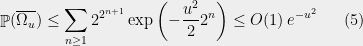
for  , since we get geometrically decreasing summands.
, since we get geometrically decreasing summands.
Write

Note that if  occurs, then
occurs, then  . Thus (5) implies that for
. Thus (5) implies that for  ,
,

which implies that

Finally, by the triangle inequality,

Plugging this into (6) recovers (3). 
Theorem 1.2 gives us a fairly natural way to upper bound the expected supremum using a hierarchical clustering of . Rather amazingly, as we’ll see in the next post, this upper bound is tight. Talagrand’s majorizing measure theorem states that if we take the best choice of in Theorem 1.2, then the upper bound in (3) is within a constant factor of  .
.

Hi James! I don’t see an earlier post about Gaussian processes, did you forget to post it?
Never mind, I found it.