In this post, I will talk about the existence and construction of subspaces of  which are “almost Euclidean.” In the next few, I’ll discuss the relationship between such subspaces, compressed sensing, and error-correcting codes over the reals.
which are “almost Euclidean.” In the next few, I’ll discuss the relationship between such subspaces, compressed sensing, and error-correcting codes over the reals.
A good starting point is Dvoretzky’s theorem:
For every  and
and 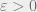 , the following holds. Let
, the following holds. Let  be the Euclidean norm on
be the Euclidean norm on  , and let
, and let  be an arbitrary norm. Then there exists a subspace
be an arbitrary norm. Then there exists a subspace 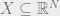 with
with 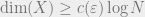 , and a number
, and a number 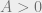 so that for every
so that for every 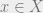 ,
,
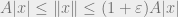 .
.
Here, 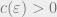 is a constant that depends only on
is a constant that depends only on  .
.
The theorem as stated is due to Vitali Milman, who gave the (optimal) dependence of  on the dimension of
on the dimension of  , and proved that the above fact actually holds with high probability when is chosen uniformly at random from all subspaces of this dimension. In other words, for
, and proved that the above fact actually holds with high probability when is chosen uniformly at random from all subspaces of this dimension. In other words, for 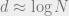 , a random
, a random 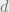 -dimensional subspace of an arbitrary
-dimensional subspace of an arbitrary 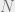 -dimensional normed space is almost Euclidean. Milman’s proof was one of the starting points for the “local theory” of Banach spaces, which views Banach spaces through the lens of sequences of finite-dimensional subspaces whose dimension goes to infinity. It’s a very TCS-like philosophy; see the book of Milman and Schechtman.
-dimensional normed space is almost Euclidean. Milman’s proof was one of the starting points for the “local theory” of Banach spaces, which views Banach spaces through the lens of sequences of finite-dimensional subspaces whose dimension goes to infinity. It’s a very TCS-like philosophy; see the book of Milman and Schechtman.
One can associate to any norm its unit ball 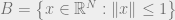 , which will be a centrally symmetric convex body. Thus we can restate Milman’s proof of Dvoretzky’s theorem geometrically: If
, which will be a centrally symmetric convex body. Thus we can restate Milman’s proof of Dvoretzky’s theorem geometrically: If 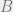 is an arbitrary convex body, and
is an arbitrary convex body, and 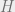 is a random
is a random 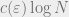 -dimensional hyperplane through the origin, then with high probability,
-dimensional hyperplane through the origin, then with high probability,  will almost be a Euclidean ball. This is quite surprising if one starts, for instance, with a polytope like the unit cube or the cross polytope. The intersection is again a polytope, but which is approximated closely by a smooth ball. Here’s a pictorial representation lifted from a talk I once gave:
will almost be a Euclidean ball. This is quite surprising if one starts, for instance, with a polytope like the unit cube or the cross polytope. The intersection is again a polytope, but which is approximated closely by a smooth ball. Here’s a pictorial representation lifted from a talk I once gave:
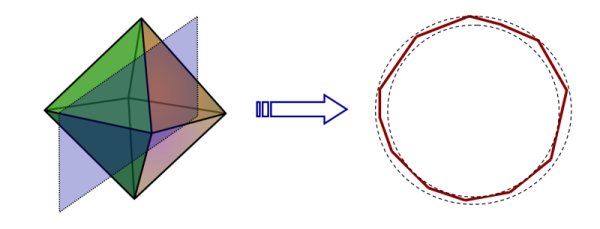
(Note: Strictly speaking, the intersection will only be an ellipsoid, and one might have to pass to a subsection to actually get a Euclidean sphere.)
Euclidean subspaces of and Error-Correcting Codes.
It is not too difficult to see that the dependence  is tight when we consider equipped with the
is tight when we consider equipped with the 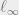 norm (see e.g. Claim 3.10 in these notes), but rather remarkably, results of Kasin and Figiel, Lindenstrauss, and Milman show that if we consider the
norm (see e.g. Claim 3.10 in these notes), but rather remarkably, results of Kasin and Figiel, Lindenstrauss, and Milman show that if we consider the  norm, we can find Euclidean subspaces of proportional dimension, i.e.
norm, we can find Euclidean subspaces of proportional dimension, i.e.  .
.
For any 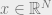 , Cauchy-Schwarz gives us
, Cauchy-Schwarz gives us
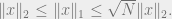
To this end, for a subspace , let’s define
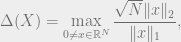
which measures how well-spread the 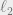 -mass is among the coordinates of vectors
-mass is among the coordinates of vectors  . For instance, if
. For instance, if  , then every non-zero
, then every non-zero 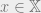 has at least
has at least 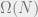 non-zero coordinates (because
non-zero coordinates (because  ). This has an obvious analogy with the setting of linear error-correcting codes, where one would like the same property from the kernel of the check matrix. Over the next few posts, I’ll show how such subspaces actually give rise to error-correcting codes over
). This has an obvious analogy with the setting of linear error-correcting codes, where one would like the same property from the kernel of the check matrix. Over the next few posts, I’ll show how such subspaces actually give rise to error-correcting codes over  that always have efficient decoding algorithms.
that always have efficient decoding algorithms.
The Kasin and Figiel-Lindenstrauss-Milman results actually describe two different regimes. Kasin shows that for every  , there exists a subspace with
, there exists a subspace with 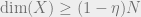 , and
, and 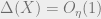 . The FLM result shows that for every , one can get
. The FLM result shows that for every , one can get 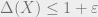 and
and 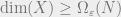 . In coding terminology, the former approach maximizes the rate of the code, while the latter maximizes the minimum distance. In this post, we will be more interested in Kasin’s “nearly full dimensional” setting, since this has the most relevance to sensing and coding. Work of Indyk (see also this) shows that the “nearly isometric” setting is useful for applications in high-dimensional nearest-neighbor search.
. In coding terminology, the former approach maximizes the rate of the code, while the latter maximizes the minimum distance. In this post, we will be more interested in Kasin’s “nearly full dimensional” setting, since this has the most relevance to sensing and coding. Work of Indyk (see also this) shows that the “nearly isometric” setting is useful for applications in high-dimensional nearest-neighbor search.
The search for explicit constructions
Both approaches show that the bounds hold for a random subspace of the proper dimension (where “random” can mean different things;we’ll see one example below). In light of this, many authors have asked whether there are explicit constructions of such subspaces exist, see e.g. Johnson and Schechtman (Section 2.2), Milman (Problem 8), and Szarek (Section 4). As I’ll discuss in future posts, this would also yield explicit constructions of codes over the reals, and of compressed sensing matrices.
Depending on the circles you run in, “explicit” can mean different things. Let’s fix a TCS-style definition: An explicit construction means a deterministic algorithm which, give as input, outputs a description of a subspace (e.g. in the form of a set of basis vectors), and runs in time  . Fortunately, the constructions I’ll discuss later will satisfy just about everyone’s sense of explicitness.
. Fortunately, the constructions I’ll discuss later will satisfy just about everyone’s sense of explicitness.
In light of the difficulty of obtaining explicit constructions, people have started looking at weaker results and partial derandomizations. One starting point is Kasin’s method of proof: He shows, for instance, that if one chooses a uniformly random 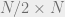 sign matrix
sign matrix  (i.e. one whose entries are chosen independently and uniformly from
(i.e. one whose entries are chosen independently and uniformly from 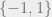 ), then with high probability, one has
), then with high probability, one has 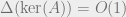 . Of course this bears a strong resemblance to random parity check codes. Clearly we also get
. Of course this bears a strong resemblance to random parity check codes. Clearly we also get 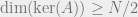 .
.
In work of Guruswami, myself, and Razborov, we show that there exist explicit sign matrices for which 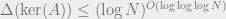 (recall that the trivial bound is
(recall that the trivial bound is 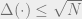 ). Our approach is inspired by the construction and analysis of expander codes. Preceding our work, Artstein-Avidan and Milman pursued a different direction, by asking whether one can reduce the dependence on the number of random bits from the trivial
). Our approach is inspired by the construction and analysis of expander codes. Preceding our work, Artstein-Avidan and Milman pursued a different direction, by asking whether one can reduce the dependence on the number of random bits from the trivial  bound (and still achieve ). Using random walks on expander graphs, they showed that one only needs
bound (and still achieve ). Using random walks on expander graphs, they showed that one only needs  random bits to construct such a subspace. Lovett and Sodin later reduced this dependency to
random bits to construct such a subspace. Lovett and Sodin later reduced this dependency to 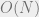 . (Indyk’s approach based on Nisan’s pseudorandom generator can also be used to get
. (Indyk’s approach based on Nisan’s pseudorandom generator can also be used to get  .) In upcoming work with Guruswami and Wigderson, we show that the dependence can be reduced to
.) In upcoming work with Guruswami and Wigderson, we show that the dependence can be reduced to  for any
for any 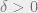 .
.
Kernels of random sign matrices
It makes sense to end this discussion with an analysis of the random case. We will prove that if is a random sign matrix (assume for simplicity that is even), then with high probability . It might help first to recall why a uniformly random matrix with  entries is almost surely the check matrix of a good linear code.
entries is almost surely the check matrix of a good linear code.
Let  be the finite field of order 2. We would like to show that, with high probability, there does not exist a non-zero vector
be the finite field of order 2. We would like to show that, with high probability, there does not exist a non-zero vector  with hamming weight
with hamming weight  , and which satisfies
, and which satisfies 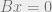 (this equation is considered over
(this equation is considered over  ). The proof is simple: Let
). The proof is simple: Let 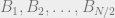 be the rows of . If
be the rows of . If  , then
, then ![\Pr[\langle B_i, x \rangle = 0] \leq \frac12.](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Clangle+B_i%2C+x+%5Crangle+%3D+0%5D+%5Cleq+%5Cfrac12.&bg=eeeeee&fg=666666&s=0&c=20201002) Therefore, for any non-zero
Therefore, for any non-zero  , we have
, we have
![\Pr[Bx = 0] \leq 2^{-N/2}.](https://s0.wp.com/latex.php?latex=%5CPr%5BBx+%3D+0%5D+%5Cleq+2%5E%7B-N%2F2%7D.&bg=eeeeee&fg=666666&s=0&c=20201002) (**)
(**)
On the other hand, for small enough, there are fewer than  non-zero vectors of hamming weight at most
non-zero vectors of hamming weight at most 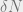 , so a union bound finishes the argument.
, so a union bound finishes the argument.
The proof that proceeds along similar lines, except that we can no longer take a naive union bound since there are now infinitely many “bad” vectors. Of course the solution is to take a sufficiently fine discretization of the set of bad vectors. This proceeds in three steps:
- If is far from
 , then any
, then any  with
with 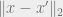 small is also far from .
small is also far from .
- Any fixed vector with
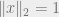 is far from with very high probability. This is the analog of (**) in the coding setting.
is far from with very high probability. This is the analog of (**) in the coding setting.
- There exists a small set of vectors that well-approximates the set of bad vectors.
Combining (1), (2), and (3) we will conclude that every bad vector is far from the kernel of (and, in particular, not contained in the kernel).
To verify (1), we need to show that almost surely the operator norm 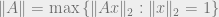 is small, because if we define
is small, because if we define
 ,
,
then
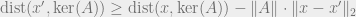
In order to proceed, we first need a tail bound on random Bernoulli sums, which follows immediately from Hoeffding’s inequality.
Lemma 1: If 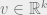 and
and 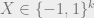 is chosen uniformly at random, then
is chosen uniformly at random, then
![\displaystyle \Pr\left[|\langle v, X \rangle| \geq t\right] \leq 2 \exp\left(\frac{-t^2}{2 \|v\|_2^2}\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%7C%5Clangle+v%2C+X+%5Crangle%7C+%5Cgeq+t%5Cright%5D+%5Cleq+2+%5Cexp%5Cleft%28%5Cfrac%7B-t%5E2%7D%7B2+%5C%7Cv%5C%7C_2%5E2%7D%5Cright%29&bg=eeeeee&fg=666666&s=0&c=20201002)
In particular, for 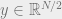 and , we have
and , we have  . We conclude that if we take and
. We conclude that if we take and 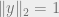 , then
, then
![\Pr\left[ |\langle y, Ax \rangle| \geq t \sqrt{2N}\right] \leq 2 \exp\left(-t^2 N\right),](https://s0.wp.com/latex.php?latex=%5CPr%5Cleft%5B+%7C%5Clangle+y%2C+Ax+%5Crangle%7C+%5Cgeq+t+%5Csqrt%7B2N%7D%5Cright%5D+%5Cleq+2+%5Cexp%5Cleft%28-t%5E2+N%5Cright%29%2C&bg=eeeeee&fg=666666&s=0&c=20201002) (4)
(4)
observing that  , and applying Lemma 1. Now we can prove that
, and applying Lemma 1. Now we can prove that  is usually not too big.
is usually not too big.
Theorem 1: If is a random sign matrix, then
![\Pr[\|A\| \geq 10 \sqrt{N}] \leq 2 e^{-6N}](https://s0.wp.com/latex.php?latex=%5CPr%5B%5C%7CA%5C%7C+%5Cgeq+10+%5Csqrt%7BN%7D%5D+%5Cleq+2+e%5E%7B-6N%7D&bg=eeeeee&fg=666666&s=0&c=20201002) .
.
Proof:
For convenience, let 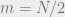 , and let
, and let  and
and  be
be  -nets on the unit spheres of
-nets on the unit spheres of 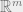 and , respectively. In other words, for every
and , respectively. In other words, for every  with , there should exist a point
with , there should exist a point 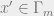 for which
for which 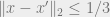 , and similarly for . It is well-known that one can choose such nets with
, and similarly for . It is well-known that one can choose such nets with  and
and  (see, e.g. the book of Milman and Schechtman mentioned earlier).
(see, e.g. the book of Milman and Schechtman mentioned earlier).
So applying (4) and a union bound, we have
![\displaystyle \Pr\left[\exists y \in \Gamma_m, x \in \Gamma_N\,\, |\langle y, Ax \rangle| \geq 3\sqrt{2N}\right] \leq 2 |\Gamma_m| |\Gamma_N| \exp(-9N) \leq 2 \exp(-6N).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%5Cexists+y+%5Cin+%5CGamma_m%2C+x+%5Cin+%5CGamma_N%5C%2C%5C%2C+%7C%5Clangle+y%2C+Ax+%5Crangle%7C+%5Cgeq+3%5Csqrt%7B2N%7D%5Cright%5D+%5Cleq+2+%7C%5CGamma_m%7C+%7C%5CGamma_N%7C+%5Cexp%28-9N%29+%5Cleq+2+%5Cexp%28-6N%29.&bg=eeeeee&fg=666666&s=0&c=20201002)
So let’s assume that no such  and
and  exist. Let
exist. Let  and
and  be arbitrary vectors with
be arbitrary vectors with 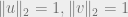 , and write
, and write  and
and 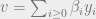 , where
, where 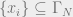 and
and  , where
, where  (by choosing successive approximations). Then we have,
(by choosing successive approximations). Then we have,
 .
.
We conclude by nothing that  .
.
This concludes the verification of (1). In the next post, we’ll see how (2) and (3) are proved.


hi james, welcome to the ToC blogosphere — you have started with a bang with such a detailed post! i have two questions about Dvoretzky’s Theorem as you have stated it: (i) as stated, your quantification allows A to be a function of N, the norm, and epsilon (as it is just a normalization) — is it independent of any of these — perhaps of both N and epsilon? or am i being silly here? (ii) since c(epsilon) is implicitly the infimum over all possible norms — is it known what the extremal norm is?
Hi Aravind,
Great questions. First, one can actually take to be the median of
to be the median of  as
as  ranges over the Euclidean sphere
ranges over the Euclidean sphere 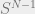 . (This hints at one of the core principles behind Milman’s proof: The value of
. (This hints at one of the core principles behind Milman’s proof: The value of  is sharply concentrated on
is sharply concentrated on 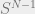 .) In particular,
.) In particular,  does not depend on
does not depend on  .
.
The extremal space for is unknown, in fact there is still a big gap between the upper and lower bounds:
is unknown, in fact there is still a big gap between the upper and lower bounds: 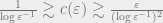 . The upper bound comes from considering the
. The upper bound comes from considering the 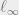 norm, and the best lower bound is due to Schechtman.
norm, and the best lower bound is due to Schechtman.