In the last post, we began proving that a random 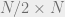

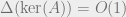

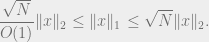
The proof follows roughly the lines of the proof that a uniformly random 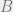




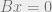
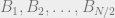

![\Pr[\langle B_i, x \rangle = 0] \leq \frac12.](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Clangle+B_i%2C+x+%5Crangle+%3D+0%5D+%5Cleq+%5Cfrac12.&bg=eeeeee&fg=666666&s=0&c=20201002)

![\Pr[Bx = 0] \leq 2^{-N/2}.](https://s0.wp.com/latex.php?latex=%5CPr%5BBx+%3D+0%5D+%5Cleq+2%5E%7B-N%2F2%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
On the other hand, for 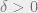

The proof that
- If
is large, and
, then
is also large.
- Any fixed vector
with
has
- There exists a small set of vectors that well-approximates the set of bad vectors.
Combining (1), (2), and (3) we will conclude that every bad vector
To verify (1), we need to show that almost surely the operator norm 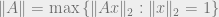
From the last post, we have the following two statements.
Lemma 1: If 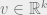
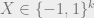
![\displaystyle \Pr\left[|\langle v, X \rangle| \geq t\right] \leq 2 \exp\left(\frac{-t^2}{2 \|v\|_2^2}\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%7C%5Clangle+v%2C+X+%5Crangle%7C+%5Cgeq+t%5Cright%5D+%5Cleq+2+%5Cexp%5Cleft%28%5Cfrac%7B-t%5E2%7D%7B2+%5C%7Cv%5C%7C_2%5E2%7D%5Cright%29&bg=eeeeee&fg=666666&s=0&c=20201002)
The next theorem (see the proof from the last post) verifies (1) above.
Theorem 1: If
![\Pr[\|A\| \geq 10 \sqrt{N}] \leq 2 e^{-6N}](https://s0.wp.com/latex.php?latex=%5CPr%5B%5C%7CA%5C%7C+%5Cgeq+10+%5Csqrt%7BN%7D%5D+%5Cleq+2+e%5E%7B-6N%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now we turn to proving (2), which is the analog of (**). We need to upper bound the small ball probability, i.e. the probability that 
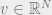
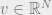

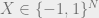
![\Pr[ |\sum_{i=1}^N X_i v_i| > 0.01] \geq 0.01](https://s0.wp.com/latex.php?latex=%5CPr%5B+%7C%5Csum_%7Bi%3D1%7D%5EN++X_i+v_i%7C+%3E+0.01%5D+%5Cgeq+0.01&bg=eeeeee&fg=666666&s=0&c=20201002)
These kinds of estimates fall under the name of Littlewood-Offord type problems; see the work of Tao and Vu and of Rudelson and Vershynin for a detailed study of such random sums, and the beautiful connections with additive combinatorics. For the above estimate, we will need only the simple Paley-Zygmund inequality:
Lemma 2: If 
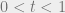
![\displaystyle \Pr[Z \geq t (\mathbb EZ)] \geq (1-t)^2 \frac{(\mathbb EZ)^2}{\mathbb E(Z^2)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5BZ+%5Cgeq+t+%28%5Cmathbb+EZ%29%5D+%5Cgeq+%281-t%29%5E2+%5Cfrac%7B%28%5Cmathbb+EZ%29%5E2%7D%7B%5Cmathbb+E%28Z%5E2%29%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof: By Cauchy-Schwarz,
![\mathbb EZ = \mathbb E[Z\mathbf{1}_{\{Z < t (\mathbb EZ)\}}] + \mathbb E[Z\mathbf{1}_{\{Z \geq t(\mathbb EZ)\}}] \leq t \mathbb E[Z] + \sqrt{\mathbb E[Z^2]} \sqrt{\mathbb E[\mathbf{1}_{\{Z \geq t (\mathbb EZ)\}}]}](https://s0.wp.com/latex.php?latex=%5Cmathbb+EZ+%3D+%5Cmathbb+E%5BZ%5Cmathbf%7B1%7D_%7B%5C%7BZ+%3C+t+%28%5Cmathbb+EZ%29%5C%7D%7D%5D+%2B+%5Cmathbb+E%5BZ%5Cmathbf%7B1%7D_%7B%5C%7BZ+%5Cgeq+t%28%5Cmathbb+EZ%29%5C%7D%7D%5D+%5Cleq+t+%5Cmathbb+E%5BZ%5D+%2B+%5Csqrt%7B%5Cmathbb+E%5BZ%5E2%5D%7D+%5Csqrt%7B%5Cmathbb+E%5B%5Cmathbf%7B1%7D_%7B%5C%7BZ+%5Cgeq+t+%28%5Cmathbb+EZ%29%5C%7D%7D%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now observe that ![\mathbb E[\mathbf{1}_{\{Z \geq t (\mathbb EZ)\}}] = \Pr[Z \geq t(\mathbb EZ)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cmathbf%7B1%7D_%7B%5C%7BZ+%5Cgeq+t+%28%5Cmathbb+EZ%29%5C%7D%7D%5D+%3D+%5CPr%5BZ+%5Cgeq+t%28%5Cmathbb+EZ%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
We can use this to prove our estimate on random sums.
Lemma 3: For any
![\displaystyle \Pr\left[|\langle X,v\rangle|^2 \geq t \|v\|_2^2 \right] \geq \frac{(1-t)^2}{12}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%7C%5Clangle+X%2Cv%5Crangle%7C%5E2+%5Cgeq+t+%5C%7Cv%5C%7C_2%5E2+%5Cright%5D+%5Cgeq+%5Cfrac%7B%281-t%29%5E2%7D%7B12%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof: Apply Lemma 2 with 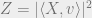
![\mathbb E[Z] = \|v\|_2^2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BZ%5D+%3D+%5C%7Cv%5C%7C_2%5E2&bg=eeeeee&fg=666666&s=0&c=20201002)

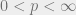
![\mathbb E[Y^p] = p \int_{0}^{\infty} \lambda^{p-1} \Pr(Y > \lambda)\,d\lambda](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY%5Ep%5D+%3D+p+%5Cint_%7B0%7D%5E%7B%5Cinfty%7D+%5Clambda%5E%7Bp-1%7D+%5CPr%28Y+%3E+%5Clambda%29%5C%2Cd%5Clambda&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle \mathbb E[Z^2] = \mathbb E[|\langle X,v\rangle|^4] = 4 \int_{0}^{\infty} \lambda^3 \Pr(|\langle X,v\rangle| > \lambda)\,d\lambda \leq 4\int_0^{\infty} \lambda^3 e^{-\lambda^2/(2\|v\|_2^2)}\,d\lambda,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BZ%5E2%5D+%3D+%5Cmathbb+E%5B%7C%5Clangle+X%2Cv%5Crangle%7C%5E4%5D+%3D+4+%5Cint_%7B0%7D%5E%7B%5Cinfty%7D+%5Clambda%5E3+%5CPr%28%7C%5Clangle+X%2Cv%5Crangle%7C+%3E+%5Clambda%29%5C%2Cd%5Clambda+%5Cleq+4%5Cint_0%5E%7B%5Cinfty%7D+%5Clambda%5E3+e%5E%7B-%5Clambda%5E2%2F%282%5C%7Cv%5C%7C_2%5E2%29%7D%5C%2Cd%5Clambda%2C&bg=eeeeee&fg=666666&s=0&c=20201002)
where the final inequality follows from Lemma 1. It is easy to see that the final bound is at most 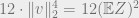
Observing that 

Corollary 1: For any
![\displaystyle \Pr\left[\vphantom{\bigoplus} \|A v\|_2 \leq \frac{\sqrt{N}}{20} \|v\|_2\right] \leq e^{-N/100}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%5Cvphantom%7B%5Cbigoplus%7D+%5C%7CA+v%5C%7C_2+%5Cleq+%5Cfrac%7B%5Csqrt%7BN%7D%7D%7B20%7D+%5C%7Cv%5C%7C_2%5Cright%5D+%5Cleq+e%5E%7B-N%2F100%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof: Apply Lemma 3 with 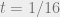
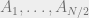
Using Theorem 1 and Corollary 1, we can verify (2):
Theorem 2: For any
![\displaystyle \Pr\left[\mathrm{dist}(v, \mathrm{ker}(A)) \leq \frac{\|v\|_2}{200}\right] \leq 3 e^{-N/100}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Cleft%5B%5Cmathrm%7Bdist%7D%28v%2C+%5Cmathrm%7Bker%7D%28A%29%29+%5Cleq+%5Cfrac%7B%5C%7Cv%5C%7C_2%7D%7B200%7D%5Cright%5D+%5Cleq+3+e%5E%7B-N%2F100%7D.&bg=eeeeee&fg=666666&s=0&c=20201002)
Proof: By Theorem 1 and Corollary 1, we may assume that 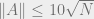



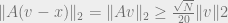
But since 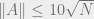

Let 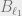


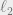

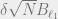

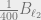
Theorem 3: There exists a constant 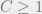
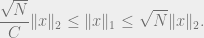
In other words,
Proof: Choose 

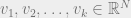
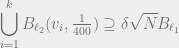
By a union bound, we can assume that 

Now suppose there exists an 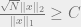

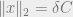

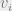


Choosing 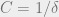
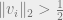
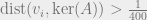
In the next post, we’ll see how such subspaces are related to error-correcting codes over the reals.

just a minor comment — in Lemma 2, all you need is that EZ >= 0, not that Z is non-negative necessarily; you can apply the Chebyshev-Cantellin inequality then (which will also lead to a slightly smaller denominator, but maybe Paley-Zygmund also leads to it).
Hi James,
Just came across this collection – it’s really nice. I hope you do keep up posting these. This is the kind of blog that’s actually worth reading.
I’m not sure I follow
dist(x’, ker(A)) >= dist(x,ker(A)) – |A||x-x’|
but it doesn’t matter much.
It seems that the equation you need (and use) is that
|x-x’| >= |A(x-x’)|/|A|
BTW I saw in your (great) powerpoint slides that you mentioned something that Milman conjectures is impossible. I hope you expand on that, and whether he conjectures an information theoretic lower bound, or that it’s hard to come up with an explicit construciton.
Boaz
Boaz, thanks; you are right that the line
dist(x’, ker(A)) >= dist(x,ker(A)) – |A||x-x’|
doesn’t make any sense, and also that the proof doesn’t use it. I have changed the description of steps (1)-(3) to reflect what actually goes on in the proof.
About Milman’s “conjecture” — it was made informally at a talk he gave last year; I believe he intended to guess that there is no completely explicit construction, but it’s not clear what that means. E.g. he would not be happy with an arbitrary deterministic polynomial time algorithm. Note that no one knows how to compute efficiently. In fact, no one knows whether
efficiently. In fact, no one knows whether  ? is in NP, or even how to give witnesses for
? is in NP, or even how to give witnesses for  . Or even how to generate random
. Or even how to generate random  ‘s that have a witness with high probability.
‘s that have a witness with high probability.
James, you forgot a sqrt(N) in the statement of theorem 3.