Here are Prasad Raghavendra‘s notes on one of two guest lectures he gave for CSE 599S. Prasad will be a faculty member at Georgia Tech after he finishes his postdoc at MSR New England.
In yet another excursion in to applications of discrete harmonic analysis, we will now see an application of the invariance principle, to hardness of approximation. We will complement this discussion with the proof of the invariance principle in the next lecture.
1. Invariance Principle
In its simplest form, the central limit theorem asserts the following: “As increases, the sum of independent bernoulli random variables ( random variables) has approximately the same distribution as the sum of independent normal (Gaussian with mean and variance ) random variables”
Alternatively, as increases, the value of the polynomial has approximately the same distribution whether the random variables are i.i.d Bernoulli random variables or i.i.d normal random variables. More generally, the distribution of is the approximately the same as long as the random variables are independent with mean , variance and satisfy certain mild regularity assumptions.
A phenomenon of this nature where the distribution of a function of random variables, depends solely on a small number of their moments is referred to as invariance.
A natural approach to generalize of the above stated central limit theorem, is to replace the “sum” () by other multivariate polynomials. As we will see in the next lecture, the invariance principle indeed holds for low degree multilinear polynomials that are not influenced heavily by any single coordinate. Formally, define the influence of a coordinate on a polynomial as follows:
Definition 1 For a multilinear polynomial define the influence of the coordinate as follows:
Here denotes the variance of over random choice of .
The invariance principle for low degree polynomials was first shown by Rotar in 1979. More recently, invariance principles for low degree polynomials were shown in different settings in the work of Mossel-O’Donnell-Olekszciewicz and Chatterjee. The former of the two works also showed the Majority is Stablest conjecture, and has been influential in introducing the powerful tool of invariance to hardness of approximation.
Here we state a special case of the invariance principle tailored to the application at hand. To this end, let us first define a rounding function as follows:
Theorem 2 (Invariance Principle [Mossel-ODonnell-Oleszkiewicz]) Let and be sets of Bernoulli and Gaussian random variables respectively. Furthermore, let
and . Let denote independent copies of the random variables and .
Let be a multilinear polynomial given by , and let . If for all , then the following statements hold:
For every function which is thrice differentiable with all its partial derivatives up to order bounded uniformly by ,
Define the function as Then, we have
2. Dictatorship Testing
A boolean function on bits is a dictator or a long code if for some . Given the truth table of a function , a dictatorship test is a randomized procedure that queries a few locations (say ) in the truth table of , and tests a predicate on the values it queried. If the queried values satisfy the predicate , the test outputs ACCEPT else it outputs REJECT. The goal of the test is to determine if is a dictator or is far from being a dictator. The main parameters of interest in a dictatorship test are :
Completeness Every dictator function is accepted with probability at least .
Soundness Any function which is far from every dictator is accepted with probability at most .
Number of queries made, and the predicate used by the test.
2.1. Motivation
The motivation for the problem of dictatorship testing arises from hardness of approximation and PCP constructions. To show that an optimization problem is -hard to approximate, one constructs a reduction from a well-known -hard problem such as Label Cover to . Given an instance of the Label Cover problem, a hardness reduction produces an instance of the problem . The instance has a large optimum value if and only if has a high optimum. Dictatorship tests serve as “gadgets” that encode solutions to the Label Cover, as solutions to the problem . In fact, constructing an appropriate dictatorship test almost always translates in to a corresponding hardness result based on the Unique Games Conjecture.
Dictatorship tests or long code tests as they are also referred to, were originally conceived purely from the insight of error correcting codes. Let us suppose we are to encode a message that could take one of different values . The long code encoding of the message is a bit string of length , consisting of the truth table of the function . This encoding is maximally redundant in that any binary encoding with more than bits would contain bits that are identical for all messages. Intuitively, greater the redundancy in the encoding, the easier it is to perform the reduction.
While long code tests/dictatorship tests were originally conceived from a coding theoretic perspective, somewhat surprisingly these objects are intimately connected to semidefinite programs. This connection between semidefinite programs and dictatorship tests is the subject of today’s lecture. In particular, we will see a black-box reduction from SDP integrality gaps for Max Cut to dictatorship tests that can be used to show hardness of approximating Max Cut.
2.2. The case of Max Cut
The nature of dictatorship test needed for a hardness reduction varies with the specific problem one is trying to show is hard. To keep things concrete and simple, we will restrict our attention to the Max Cut problem.
A dictatorship test for the Max Cut problem consists of a graph on the set of vertices . By convention, the graph is a weighted graph where the edge weights form a probability distribution (sum up to ). We will write to denote an edge sampled from the graph (here ).
A cut of the graph can be thought of as a boolean function . For a boolean function , let denote the value of the cut. The value of a cut is given by
It is useful to define , for non-boolean functions that take values in the interval . To this end, we will interpret a value as a random variable that takes values. Specifically, we think of a number as the following random variable
$ latex a = -1 $ with probability and with probability $\frac{1+a}{2}$.
With this interpretation, the natural definition of is as follows:
Indeed, the above expression is equal to the expected value of the cut obtained by randomly rounding the values of the function to as described in Equation 2.
A Dictator Cut
The dictator cuts are given by the functions for some . The of the test is the minimum value of a dictator cut, i.e.,
The soundness of the dictatorship test is the value of cuts that are far from every dictator. We will formalize the notion of being far from every dictator is formalized using influences as follows:
Cut Far From Every Dictator
Definition 3 (-quasirandom) A function is said to be -quasirandom if for all , .
Definition 4 () For a dictatorship test over and , define the soundness of as
2.3. SDP Relaxation
Let be an an instance of the Max Cut problem. Specifically, is a weighted graph over a set of vertices , whose edge weights sum up to (by convention). Thus, the set of edges will also be thought of as a probability distribution over edges. Let us the Goemans-Williamson semidefinite programming relaxation for Max Cut. The variables of the GW SDP consist of a set of vectors , one vector for each vertex in the graph .
GW SDP Relaxation
Maximize (Average Squared Length of Edges)
Subject to (all vectors $\latex \mathbf v_i\ $ are unit vectors)
3. Intuition
Let be an an arbitrary instance of the Max Cut problem and let denote a feasible solution to the GW SDP relaxation. We begin by presenting the intuition behind the black box reduction.
3.1. Dimension Reduction
Without loss of generality, the SDP solution can be assumed to lie in a large constant dimensional space. Specifically, given an arbitrary SDP solution in -dimensional space, project it in to a random subspace of dimension – a large constant. Random projections approximately preserve the lengths of vectors and distances between them. Hence, roughly speaking, the vectors produced after random projection yield a low-dimensional SDP solution to the same graph .
Formally, sample random Gaussian vectors of the same dimension as the SDP vectors . Here is to be thought of as a large constant independent of the size of the graph . Define a solution to the GW SDP relaxation as follows:
for all vertices in graph $latex G$
The vector is just the projection of the vector along directions , normalized to unit length. Clearly, the vectors form a feasible SDP solution to GW SDP.
For every , by choosing to be a sufficiently large constant, the following can be ensured: the distance between any two vectors and is preserved up to -multiplicative factor with probability at least . Therefore, there exists some choice of such that the vectors form a low dimensional SDP solution with roughly the same value as , i.e., . Henceforth, without loss of generality, let us assume that the SDP solution consist of -dimensional vectors for a large enough constant .
3.2. Sphere Graph
A graph on the unit sphere, will consist of a set of unit vectors, and weigthed edges between them. As usual, the weights of the graph form a probability distribution, in that they sum up to .
The SDP solution for a graph , yields a graph on the -dimensional unit sphere, which is isomorphic to . Recall that the objective value of the GW SDP is the average squared length of the edges. Hence, the SDP value remains unchanged under the following transformations:
Rotation Any rotation of the SDP vectors about the origin, preserves the lengths of edges, and the distances between them. Thus, rotating the SDP solution yields another feasible solution with the same objective value.
Union of Rotations Let and be two solutions obtained by applying rotations to the SDP vectors . Let be the associated graphs on the unit sphere. Let denote the union of the two graphs, i.e., . The set of all distinct vectors in are the vertices of . The edge distribution of is the average of the edge distributions of and .The average squared lengths of edges in both and are equal to . Hence, the average squared edge length in is also equal to . Thus, taking the union of two rotations of a graph preserves the SDP value.
Define the sphere graph as follows:
Constructing the Sphere Graph
Sphere Graph : Union of all possible rotations of the graph (on the set of vectors ) on the -dimensional unit sphere.
Clearly the sphere graph is an infinite graph. The sphere graph is solely a conceptual tool, and an explicit representation is never needed in the reduction. Nevertheless, due to its symmetry, indeed the sphere graph can be represented succinctly. By construction, the SDP value of the sphere graph is the same as that of the original graph . However, we will argue that is a harder instance of Max Cut than the original graph . In fact, given a cut for the sphere graph , it is possible to retrieve a cut for the original graph with the same objective value. Let us suppose is a cut of the sphere graph that cuts a -fraction of the edges. Notice that consists of a union of infinitely many copies (or rotations) of the graph . Therefore, on at least one of the copies of , the cut must cut a -fraction of the edges. Indeed, if we have oracle access to the cut function , we can efficiently construct a cut of the graph with the same value as using the following rounding procedure:
Sample a rotation of the unit sphere, uniformly at random.
Output the cut induced by on the copy of the graph .
The expected value of the cut output by the procedure is equal to the value of the cut on the sphere graph . An immediate consequence is that,
The sphere graph inherits the same SDP value as , while the optimum value is at most that of the graph . In this light, the sphere graph is a harder instance of Max Cut than the original graph .
It is easy to see that the following is an equivalent definition for the sphere graph .
Definition 5 (Sphere Graph ) The set of vertices of is the set of all points on the -dimensional unit sphere. To sample an edge of use the following procedure,
Sample an edge in the graph ,
Sample two points on the sphere at a squared distance uniformly at random.
Output the edge between .
3.3. Hypercube Graph
Finally, we are ready to describe the construction of the graph on the -dimensional hypercube. Here we refer to the hypercube suitably normalized to make all its points lie on the unit sphere.
The set of vertices of are points in . An edge of can be sampled as follows:
Sample an edge in the graph .
Sample two points in , at squared distance uniformly at random.
Output the edge between .
It is likely that there are no pair of points on the hypercube at a distance exactly equal to . For the sake of exposition, let us ignore this issue for now. To remedy this issue, in the final construction, for each edge just introduce a probability distribution over edges such that the expected length of an edge is indeed .
Completeness:
Consider the th dictator cut given . This corresponds to the axis-parallel cut of the graph along the th axis of the hypercube. Let us estimate the value of the cut . An edge is cut by the th dictator cut if and only if . Therefore, the value of the th dictator cut is given by:
Notice that two points at a squared distance differ on exactly coordinates. Hence, two random points at distance at a squared distance differ on a given coordinate with probability . Therefore, let us rewrite the expression for as follows:
Hence, is at least .
Soundness:
Consider a cut that is far from every dictator. Intuitively, the cut is not parallel to any of the axis of the hypercube. Note the strong similarity in the construction of the sphere graph and the hypercube graph . In both cases, we sampled two random points at a distance equal to the edge length. In fact, the hypercube graph is a subgraph of the sphere graph . The existence of special directions (the axis of the hypercube) is what distinguishes the hypercube graph from the sphere graph . Thus, roughly speaking, a cut which is not paralel to any axis must be unable to distinguish between the sphere graph and the hypercube graph . If we visualize the cut of as a geometric surface not parallel to any axis, then the same geometric surface viewed as a cut
Extending the cut from Hypercube to Sphere graph
of the sphere graph must separate roughly the same fraction of edges.
Indeed, the above intuition can be made precise if the cut is sufficiently smooth (low degree). The cut can be expressed as a multilinear polynomial (by Fourier expansion), thus extending the cut function from to . The function is smooth if the corresponding polynomial polynomial is low degree. If is smooth and far from every dictator, then one can show that,
By Equation 1, the maximum value of a cut of the sphere graph is at most . Therefore, for any cut that is smooth and far from every dictator, we get .
Ignoring the smoothness condition for now, the above argument shows that the soundness of the dictatorship test is at most . Summarizing the above discussion, starting from a SDP solution for a graph , we constructed hypercube graph (dictatorship test) such that , and .
By suitably modifying the construction of , the smoothness requirement for the cut can be dropped. The basic idea is fairly simple yet powerful. In the definition of , while introducing an edge between , perturb each coordinate of and with a tiny probability to obtain and respectively, then introduce the edge instead of . The introduction of noise to the vertices and has an averaging effect on the cut function, thus making it smooth.
4. Formal Proof
Let be an arbitrary instance of Max Cut. Let be a feasible solution to the SDP relaxation.
Locally, for every edge in , there exists a distribution over assignments that match the SDP inner products. In other words, there exists valued random variables such that
For each edge , let denote the local integral distribution over assignments.
The details of the construction of dictatorship test are as follows:
The set of vertices of consist of the -dimensional hypercube . The distribution of edges in is the one induced by the following sampling procedure:
Sample an edge in the graph .
Sample times independently from the distribution to obtain and , both in .
Perturb each coordinate of and independently with probability to obtain respectively. Formally, for each ,
Output the edge .
Theorem 6 There exists absolute constants such that for all , for any graph and an SDP solution for the GW-SDP relaxation of ,
Let be a cut of the graph. The fraction of edges cut by is given by
4.1. Completeness
Consider the th dictator cut given by . With probability , the perturbation does not affect the th coordinate of and . In other words, with probability , the following hold: and . Hence,
Observe that if the edge in is sampled, then the distribution is used to generate each coordinates of and . Specifically, this means that the coordinates and satisfy,
Therefore, .
4.2. Soundness
For the sake of analysis, let us construct a graph , roughly similar to the sphere graph described earlier. Gaussian Graph
The vertices of are points in . The graph is the union of all random projections of the SDP solution in to dimensions. Formally, an edge of can be sampled as follows:
Sample random Gaussian vectors of the same dimension as the SDP solution .
Project the SDP vectors along directions to obtain a copy of in a . Formally define,
Sample an edge in , and output the corresponding edge in
As lengths of vectors are approximately preserved under random projections, most of the vectors are are roughly unit vectors. Hence, the Gaussian graph is a slightly fudged version of the sphere graph described earlier.
As the graph consists of a union of several isomorphic copies of , the following claim is an immediate consequence.
Claim 1
Let us suppose be a -quasirandom function. For the sake of succinctness, let us denote . Essentially, is the expected value returned by on querying a perturbation of the input . Thus the function is a smooth version of , obtained by averaging the values of .
Now we will extend the cut from the hypercube graph to the Gaussian graph . To this end, write the functions as written as a multilinear polynomials in the coordinates of . In particular, the Fourier expansion of and yields the intended multilinear polynomials.
The polynomials and yield natural extension of the cut functions and from to . However, unlike the original cut function , the range of its extension need not be restricted to . To ensure that the extension defines a cut of the graph , let us round the extension in the most natural fashion using . Specifically, the extension of the cut to is given by
where
Let denote the value of the cut of the graph . Now we can show the following claim.
Claim 2 For a -quasirandom function ,
By definition of , we have . Along with Claim 1, this implies that , completing the proof of Theorem 6.
Proof: [Proof of Claim 2] Returning to the definition of , notice that the random variable depends only on . Thus, the value of a cut can be rewritten as,
By the definition of the noise operator ,. Hence can be rewritten as
By definition of the Gaussian graph , we have
Firstly, let us denote by the function given by . Let us restrict our attention to a particular edge . For this edge, we will show that
By averaging the above equality over all edges in the graph , the claim follows. We will use the invariance principle to show the above claim.
By design, for each edge the pairs of random variables and satisfy,
The predicate/payoff is currently defined as in the domain . Extend the payoff to a smooth function over the entire space , with all its partial derivatives up to order bounded uniformly throughout . Notice that the function by itself does not have uniformly bounded derivatives in . Further, it is easy to ensure that the extension satisfies the following Lipschitz condition for some large enough constant ,
Step I : Apply the invariance principle with the ensembles and , for the vector of multilinear polynomials and the smooth function . This yields,
Step II : In this step, let us bound the effect of the rounding operation used in extending the cut from to .
As is a cut of , its range is . Hence, the corresponding polynomial takes values on inputs from . As is an average of the values of , the values and are always in the range .
By the invariance principle, the random variable has approximately the same behaviour as . Roughly speaking, this implies that the values are also nearly always in the range . Hence, intuitively the rounding operation must have little effect on the value of the cut.
This intuition is formalized by the second claim in the invariance principle. The function measures the squared deviation from the range . For random variables , clearly we have . By the invariance principle applied to polynomial we get,
Using the Lipschitz condition satisfied by the payoff,
Along with Equation 4, the above inequality implies Equation 4. This finishes the proof of Claim 2.
5. Dictatorship Tests and Rounding Schemes
The soundness analysis can be translated in to an efficient rounding scheme. Specifically, given a cut of the graph , let denote the extension of the cut to the Gaussian graph . The idea is to sample a random copy of the graph inside the Gaussian graph , and output the cut induced by on the copy. The details of the rounding scheme so obtained are as follows:
Input: SDP solution for the GW SDP relaxation of the graph .
Sample random Gaussian vectors of the same dimension as the SDP solution .
Project the SDP vectors along directions . Let
Compute for all as where
Assign vertex , the value with probability and with the remaining probability.
Let denote the expected value of the cut returned by the above rounding scheme on an SDP solution . Then,
The following is an immediate consequence of Claim 2,
Theorem 7 For a -quasirandom function ,
The above theorem exposes an interesting duality between rounding schemes and dictatorship tests.


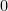
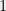




define the influence of the
coordinate as follows:
denotes the variance of
over random choice of
.
![{ \mathrm{Inf}_{i}(F) = \mathop{\mathbb E}_{x} [\mathrm{Var}_{x^{(i)}}[F]] = \sum_{\sigma_{i} \neq 0} \hat{F}^2_\sigma}](https://s0.wp.com/latex.php?latex=%7B%09%5Cmathrm%7BInf%7D_%7Bi%7D%28F%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bx%7D+%5B%5Cmathrm%7BVar%7D_%7Bx%5E%7B%28i%29%7D%7D%5BF%5D%5D+%3D+%5Csum_%7B%5Csigma_%7Bi%7D+%5Cneq+%090%7D+%5Chat%7BF%7D%5E2_%5Csigma%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{f_{[-1,1]}}](https://s0.wp.com/latex.php?latex=%7Bf_%7B%5B-1%2C1%5D%7D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle f_{[-1,1]}(x) = \begin{cases} -1 &\text{ if } x < -1 \\ x &\text{ if } -1\leqslant x\leqslant 1 \\ 1 &\text{ if } x > 1 \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_%7B%5B-1%2C1%5D%7D%28x%29+%3D+%5Cbegin%7Bcases%7D+-1+%26%5Ctext%7B+if+%7D+x+%3C+-1+%5C%5C+x+%26%5Ctext%7B+if+%7D+-1%5Cleqslant+x%5Cleqslant+1+%5C%5C+1+%26%5Ctext%7B+if+%7D+x+%3E+1+%5Cend%7Bcases%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
and
be sets of Bernoulli and Gaussian random variables respectively. Furthermore, let
. Let
denote
independent copies of the random variables
and
.
be a multilinear polynomial given by
, and let
. If
for all
, then the following statements hold:
which is thrice differentiable with all its partial derivatives up to order
bounded uniformly by
,
as
Then, we have
![{ \Big|\mathop{\mathbb E}[\xi(H(\mathbf{z}_1^{n}), H(\mathbf{z}_2^{n}))] - \mathop{\mathbb E}[\xi(H(\mathbf{g}_1^{n}),H(\mathbf{g}_2^{n}))] \Big| \leqslant \tau^{O(\epsilon)} }](https://s0.wp.com/latex.php?latex=%7B+%5CBig%7C%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cxi%28H%28%5Cmathbf%7Bz%7D_1%5E%7Bn%7D%29%2C+H%28%5Cmathbf%7Bz%7D_2%5E%7Bn%7D%29%29%5D+-+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cxi%28H%28%5Cmathbf%7Bg%7D_1%5E%7Bn%7D%29%2CH%28%5Cmathbf%7Bg%7D_2%5E%7Bn%7D%29%29%5D+%5CBig%7C+%5Cleqslant+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb E}[z_i] = \mathop{\mathbb E}[g_i] = 0 \qquad \qquad \mathop{\mathbb E}[z_i^2] = \mathop{\mathbb E}[g_i^2] = 1 \qquad \qquad \forall i \in [2]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D%5Bz_i%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Bg_i%5D+%3D+0+%5Cqquad+%5Cqquad+%5Cmathop%7B%5Cmathbb+E%7D%5Bz_i%5E2%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Bg_i%5E2%5D+%3D+1+%5Cqquad+%5Cqquad+%5Cforall+i+%5Cin+%5B2%5D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \Big|\mathop{\mathbb E}\Big[\Psi(H(\mathbf{z}_1^{R}), H(\mathbf{z}_2^{R}))\Big] - \mathop{\mathbb E}\Big[\Psi(H(\mathbf{g}_1^R), H(\mathbf{g}_2^R))\Big] \Big| \leqslant \tau^{O(\epsilon)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CBig%7C%5Cmathop%7B%5Cmathbb+E%7D%5CBig%5B%5CPsi%28H%28%5Cmathbf%7Bz%7D_1%5E%7BR%7D%29%2C+%09+H%28%5Cmathbf%7Bz%7D_2%5E%7BR%7D%29%29%5CBig%5D+-+%5Cmathop%7B%5Cmathbb+E%7D%5CBig%5B%5CPsi%28H%28%5Cmathbf%7Bg%7D_1%5ER%29%2C+H%28%5Cmathbf%7Bg%7D_2%5ER%29%29%5CBig%5D+%5CBig%7C+%5Cleqslant+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+&bg=eeeeee&fg=000000&s=0&c=20201002)

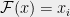
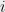
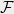
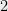

Every dictator function
.
Any function
.



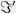
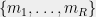
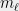
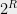

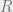
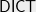
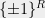

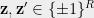
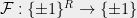

![\displaystyle \mathsf{DICT}(\mathcal{F}) = \frac{1}{2}\mathop{\mathbb E}_{ (\mathbf{z}, \mathbf{z}')} \Big[ 1 - \mathcal{F}(\mathbf{z}) \mathcal{F}(\mathbf{z}') \Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BDICT%7D%28%5Cmathcal%7BF%7D%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B+%28%5Cmathbf%7Bz%7D%2C+%5Cmathbf%7Bz%7D%27%29%7D+%5CBig%5B+%09%091+-+%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%29+%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%27%29+%5CBig%5D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{\mathcal{F}: \{\pm 1\}^R \rightarrow [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BF%7D%3A+%5C%7B%5Cpm+1%5C%7D%5ER+%5Crightarrow+%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![{\mathcal{F}(\mathbf{z}) \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%29+%5Cin+%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

![{a \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Ba+%09%5Cin+%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
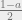

![\displaystyle \mathsf{DICT}(\mathcal{F}) = \frac{1}{2}\mathop{\mathbb E}_{ (\mathbf{z}, \mathbf{z}') \in \mathsf{DICT}} \Big[ 1 - \mathcal{F}(\mathbf{z}) \mathcal{F}(\mathbf{z}') \Big] {\,.}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BDICT%7D%28%5Cmathcal%7BF%7D%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B+%28%5Cmathbf%7Bz%7D%2C+%5Cmathbf%7Bz%7D%27%29+%5Cin+%09%5Cmathsf%7BDICT%7D%7D+%5CBig%5B+%09%091+-+%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%29+%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%27%29+%5CBig%5D+%7B%5C%2C.%7D+&bg=eeeeee&fg=000000&s=0&c=20201002)
![{\mathcal{F} : \{\pm 1\}^{R} \rightarrow [-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BF%7D+%3A+%5C%7B%5Cpm+1%5C%7D%5E%7BR%7D+%5Crightarrow+%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)


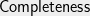
![\displaystyle \mathsf{Completeness}(\mathsf{DICT}) = \min_{\ell \in [R]} \mathsf{DICT}(z_{\ell})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BCompleteness%7D%28%5Cmathsf%7BDICT%7D%29+%3D+%5Cmin_%7B%5Cell+%5Cin+%5BR%5D%7D+%09%5Cmathsf%7BDICT%7D%28z_%7B%5Cell%7D%29+&bg=eeeeee&fg=000000&s=0&c=20201002)

-quasirandom) A function
is said to be
,
.
) For a dictatorship test
, define the soundness of

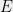
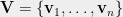
(Average Squared Length of Edges)
(all vectors $\latex \mathbf v_i\ $ are unit vectors)

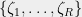

![\displaystyle \mathbf w_i = \frac{1}{\sqrt{\sum_{j \in [R]} {\langle{ \mathbf v_i, \mathbf \zeta_j} \rangle}^2}} \Big( \langle{\mathbf v_i, \mathbf \zeta_1}\rangle\ldots\langle{\mathbf v_i, \mathbf \zeta_R}\rangle\Big)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf+w_i+%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7B%5Csum_%7Bj+%5Cin+%5BR%5D%7D+%09%09%7B%5Clangle%7B+%5Cmathbf+%09%09v_i%2C+%5Cmathbf+%5Czeta_j%7D+%5Crangle%7D%5E2%7D%7D+%5CBig%28+%5Clangle%7B%5Cmathbf+v_i%2C+%09%09%5Cmathbf+%5Czeta_1%7D%5Crangle%5Cldots%5Clangle%7B%5Cmathbf+v_i%2C+%5Cmathbf+%5Czeta_R%7D%5Crangle%5CBig%29+&bg=eeeeee&fg=666666&s=0&c=20201002)
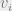

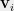


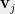



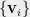
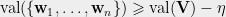

and
be two solutions obtained by applying rotations
to the SDP vectors
be the associated graphs on the unit sphere. Let
denote the union of the two graphs, i.e.,
. The set of all distinct vectors in
are the vertices of
and
.The average squared lengths of edges in both
and
are equal to
. Hence, the average squared edge length in
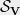


of the unit sphere, uniformly at random.
on the copy
of the graph

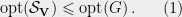

in the graph
on the sphere at a squared distance
uniformly at random.
.
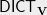
. An edge of
in
, at squared distance
uniformly at random.
.

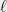



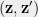
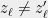
![\mathsf{DICT}_{\mathbf{V}}(\mathcal{F}) = \mathop{\mathbb E}_{(v_i, v_j) \in G} \mathop{\mathbb E}_{\mathbf{z},\mathbf{z}'} \Big[ \mathbf{1}[z_\ell\neq z'_\ell]\Big]](https://s0.wp.com/latex.php?latex=%5Cmathsf%7BDICT%7D_%7B%5Cmathbf%7BV%7D%7D%28%5Cmathcal%7BF%7D%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%28v_i%2C+v_j%29+%5Cin+G%7D+%09%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%2C%5Cmathbf%7Bz%7D%27%7D+%5CBig%5B+%5Cmathbf%7B1%7D%5Bz_%5Cell%5Cneq+z%27_%5Cell%5D%5CBig%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
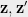


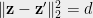
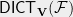
![\displaystyle \mathsf{DICT}_{\mathbf V}(\mathcal{F})=\frac{1}{4}\mathop{\mathbb E}_{(v_i,v_j)\in G}\Big[\lVert{\mathbf v_i - \mathbf v_j}\rVert_2^2\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29%3D%5Cfrac%7B1%7D%7B4%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B%28v_i%2Cv_j%29%5Cin+G%7D%5CBig%5B%5ClVert%7B%5Cmathbf+v_i+-+%5Cmathbf+v_j%7D%5CrVert_2%5E2%5CBig%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle=\frac{1}{2}\mathop{\mathbb{E}}_{(v_i, v_j) \in G}\Big[ 1 -\langle{\mathbf{v}_i, \mathbf{v}_j}\rangle\Big]=\mathrm{val}(\mathbf{V})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%3D%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%28v_i%2C+v_j%29+%5Cin+G%7D%5CBig%5B+1+-%5Clangle%7B%5Cmathbf%7Bv%7D_i%2C+%5Cmathbf%7Bv%7D_j%7D%5Crangle%5CBig%5D%3D%5Cmathrm%7Bval%7D%28%5Cmathbf%7BV%7D%29+&bg=eeeeee&fg=666666&s=0&c=20201002)
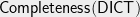


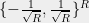

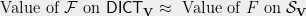



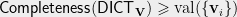



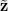




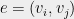
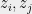
![\displaystyle \mathbf v_i \cdot \mathbf v_j = \mathop{\mathbb E}[z_i \cdot z_j]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathbf+v_i+%5Ccdot+%5Cmathbf+v_j+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Bz_i+%5Ccdot+z_j%5D&bg=eeeeee&fg=000000&s=0&c=20201002)


in the graph
and
, both in
and
independently with probability
respectively. Formally, for each
.
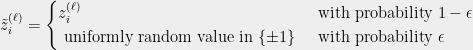
such that for all
, for any graph


![\displaystyle \mathsf{DICT}_{\mathbf V}(\mathcal{F})=\frac{1}{2}\mathop{\mathbb E}_{(v_i,v_j) \in E} \mathop{\mathbb E}_{\mathbf{z}^R_{i}, \mathbf{z}^R_j}\mathop{\mathbb E}_{\tilde{\mathbf{z}}_i^R, \tilde{\mathbf{z}}_j^R}\Big[1-\mathcal{F}(\tilde{\mathbf{z}}_i^R) \cdot \mathcal{F}(\tilde{\mathbf{z}}_j^R)\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29%3D%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B%28v_i%2Cv_j%29+%5Cin+E%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bz%7D%5ER_j%7D%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_i%5ER%2C+%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_j%5ER%7D%5CBig%5B1-%5Cmathcal%7BF%7D%28%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_i%5ER%29+%5Ccdot+%5Cmathcal%7BF%7D%28%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_j%5ER%29%5CBig%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
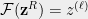

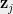


![\displaystyle \mathsf{DICT}_{\mathbf V}(\mathcal{F}) \geqslant (1-\epsilon)^2 \cdot \frac{1}{2}\mathop{\mathbb E}_{e} \mathop{\mathbb E}_{\mathbf{z}^R_{i}, \mathbf{z}^R_j} \Big[1 - {z}_i^{(\ell)} \cdot {z}_j^{(\ell)}\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29+%5Cgeqslant+%281-%5Cepsilon%29%5E2+%5Ccdot+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bz%7D%5ER_j%7D+%5CBig%5B1+-+%7Bz%7D_i%5E%7B%28%5Cell%29%7D+%5Ccdot+%7Bz%7D_j%5E%7B%28%5Cell%29%7D%5CBig%5D+&bg=eeeeee&fg=000000&s=0&c=20201002)

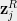


![\displaystyle \mathop{\mathbb E}_{\mathbf{z}_i^R, \mathbf{z}_j^R} \Big[ 1 - z_i^{(\ell)} \cdot z_j^{(\ell)}\Big] = \mathop{\mathbb E}_{\mu_e} [1-z_i^{(\ell)} \cdot z_j^{(\ell)}] = 1 - \langle{ \mathbf v_i , \mathbf v_j}\rangle {\,.}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D_i%5ER%2C+%5Cmathbf%7Bz%7D_j%5ER%7D+%5CBig%5B+1+-+z_i%5E%7B%28%5Cell%29%7D+%5Ccdot+z_j%5E%7B%28%5Cell%29%7D%5CBig%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D+%5B1-z_i%5E%7B%28%5Cell%29%7D+%5Ccdot+z_j%5E%7B%28%5Cell%29%7D%5D+%3D+1+-+%5Clangle%7B+%5Cmathbf+v_i+%2C+%5Cmathbf+v_j%7D%5Crangle+%7B%5C%2C.%7D+&bg=eeeeee&fg=000000&s=0&c=20201002)
![{ \mathsf{DICT}_{\mathbf V}(\mathcal{F}) \geqslant (1-\epsilon)^2 \cdot \frac{1}{2}\mathop{\mathbb E}_{e} \left[1 - \langle{ \mathbf v_i ,\mathbf v_j}\rangle\right] \geqslant (1-\epsilon)^2 \cdot \mathrm{val}(\mathbf V)}](https://s0.wp.com/latex.php?latex=%7B+%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29+%5Cgeqslant+%281-%5Cepsilon%29%5E2+%5Ccdot+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%7D+%5Cleft%5B1+-+%5Clangle%7B+%5Cmathbf+v_i+%2C%5Cmathbf+v_j%7D%5Crangle%5Cright%5D+%5Cgeqslant+%281-%5Cepsilon%29%5E2+%5Ccdot+%5Cmathrm%7Bval%7D%28%5Cmathbf+V%29%7D&bg=eeeeee&fg=000000&s=0&c=20201002)

of the same dimension as the SDP solution
along directions
to obtain a copy of
in
in

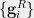
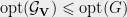





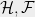




![f_{[-1,1]}](https://s0.wp.com/latex.php?latex=f_%7B%5B-1%2C1%5D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
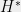
![\displaystyle H^{*}(\mathbf{g}^{R}) = f_{[-1,1]}(H(\mathbf{g}^{R}))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%5E%7B%2A%7D%28%5Cmathbf%7Bg%7D%5E%7BR%7D%29+%3D+f_%7B%5B-1%2C1%5D%7D%28H%28%5Cmathbf%7Bg%7D%5E%7BR%7D%29%29+&bg=eeeeee&fg=666666&s=0&c=20201002)
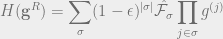

,
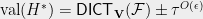


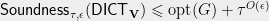


![\displaystyle \mathsf{DICT}_{\mathbf V}(\mathcal{F}) = \frac{1}{2}\mathop{\mathbb E}_{e} \mathop{\mathbb E}_{\mathbf{z}^R_{i}, \mathbf{z}^R_j} \Big[ 1 - \mathop{\mathbb E}_{\tilde{\mathbf{z}}_i^R}[\mathcal{F}(\tilde{\mathbf{z}}_i^{R})| \mathbf{z}_i^{R}] \cdot \mathop{\mathbb E}_{\tilde{\mathbf{z}}_j^R}[\mathcal{F}(\tilde{\mathbf{z}}_j^R)| \mathbf{z}_j^{R}] \Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bz%7D%5ER_j%7D+%5CBig%5B+1+-+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_i%5ER%7D%5B%5Cmathcal%7BF%7D%28%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_i%5E%7BR%7D%29%7C+%5Cmathbf%7Bz%7D_i%5E%7BR%7D%5D+%5Ccdot+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_j%5ER%7D%5B%5Cmathcal%7BF%7D%28%5Ctilde%7B%5Cmathbf%7Bz%7D%7D_j%5ER%29%7C+%5Cmathbf%7Bz%7D_j%5E%7BR%7D%5D+%5CBig%5D+&bg=eeeeee&fg=000000&s=0&c=20201002)
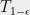
![{ T_{1-\epsilon} \mathcal{F}(\mathbf{z}^{R}) = \mathop{\mathbb E}_{\tilde{z}^R}[\mathcal{F}(\tilde{\mathbf{z}}^R)|\mathbf{z}^{R}] }](https://s0.wp.com/latex.php?latex=%7B+T_%7B1-%5Cepsilon%7D+%5Cmathcal%7BF%7D%28%5Cmathbf%7Bz%7D%5E%7BR%7D%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Ctilde%7Bz%7D%5ER%7D%5B%5Cmathcal%7BF%7D%28%5Ctilde%7B%5Cmathbf%7Bz%7D%7D%5ER%29%7C%5Cmathbf%7Bz%7D%5E%7BR%7D%5D+%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \mathsf{DICT}_{\mathbf V}(\mathcal{F}) = \frac{1}{2}\mathop{\mathbb E}_{e =(v_i,v_j)} \mathop{\mathbb E}_{\mathbf{z}^R_{i}, \mathbf{z}^R_j} \Big[ 1 - \mathcal{H}({\mathbf{z}}_i^{R}) \cdot \mathcal{H}({\mathbf{z}}_j^R)\Big] = \frac{1}{2}\mathop{\mathbb E}_{e=(v_i,v_j)} \mathop{\mathbb{E}}_{\mathbf{z}^R_{i}, \mathbf{z}^R_j} \Big[ 1 - H({\mathbf{z}}_i^{R}) \cdot H({\mathbf{z}}_j^R)\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathsf%7BDICT%7D_%7B%5Cmathbf+V%7D%28%5Cmathcal%7BF%7D%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be+%3D%28v_i%2Cv_j%29%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bz%7D%5ER_j%7D+%5CBig%5B+1+-+%5Cmathcal%7BH%7D%28%7B%5Cmathbf%7Bz%7D%7D_i%5E%7BR%7D%29+%5Ccdot+%5Cmathcal%7BH%7D%28%7B%5Cmathbf%7Bz%7D%7D_j%5ER%29%5CBig%5D+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%3D%28v_i%2Cv_j%29%7D+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bz%7D%5ER_j%7D+%5CBig%5B+1+-+H%28%7B%5Cmathbf%7Bz%7D%7D_i%5E%7BR%7D%29+%5Ccdot+H%28%7B%5Cmathbf%7Bz%7D%7D_j%5ER%29%5CBig%5D+&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{val}(H^*) = \frac{1}{2}\mathop{\mathbb E}_{e=(v_i,v_j)} \mathop{\mathbb E}_{\mathbf{g}^R_{i}, \mathbf{g}^R_j} \Big[ 1 - H^*({\mathbf{g}}_i^{R}) \cdot H^*({\mathbf{g}}_j^R)\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7Bval%7D%28H%5E%2A%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%3D%28v_i%2Cv_j%29%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bg%7D%5ER_j%7D+%5CBig%5B+1+-+H%5E%2A%28%7B%5Cmathbf%7Bg%7D%7D_i%5E%7BR%7D%29+%5Ccdot+H%5E%2A%28%7B%5Cmathbf%7Bg%7D%7D_j%5ER%29%5CBig%5D+&bg=eeeeee&fg=000000&s=0&c=20201002)
![{P : [-1,1]^2 \rightarrow [-1,1]}](https://s0.wp.com/latex.php?latex=%7BP+%3A+%5B-1%2C1%5D%5E2+%5Crightarrow+%5B-1%2C1%5D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)


![\displaystyle \mathop{\mathbb E}_{\mathbf{z}_1^R, \mathbf{z}_2^R} \big[P(H(\mathbf{z}_1^R),H(\mathbf{z}_2^R))\big] = \mathop{\mathbb E}_{\mathbf{g}_1^R, \mathbf{g}_2^R} \big[P\left(H^*(\mathbf{g}_1^{R}),H^*(\mathbf{g}_2^{R})\right)\big] \pm \tau^{O(\epsilon)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D_1%5ER%2C%09+%5Cmathbf%7Bz%7D_2%5ER%7D+%09%5Cbig%5BP%28H%28%5Cmathbf%7Bz%7D_1%5ER%29%2CH%28%5Cmathbf%7Bz%7D_2%5ER%29%29%5Cbig%5D+%09%3D+%09%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bg%7D_1%5ER%2C+%5Cmathbf%7Bg%7D_2%5ER%7D+%09%5Cbig%5BP%5Cleft%28H%5E%2A%28%5Cmathbf%7Bg%7D_1%5E%7BR%7D%29%2CH%5E%2A%28%5Cmathbf%7Bg%7D_2%5E%7BR%7D%29%5Cright%29%5Cbig%5D+%09%5Cpm+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)


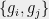
![\displaystyle \mathop{\mathbb E}_{\mathbf \zeta}[g_i] = \mathop{\mathbb E}_{\mu_e}[z_i] = 0 \qquad \qquad \mathop{\mathbb E}_{\mathbf \zeta}[g_i^2] = \mathop{\mathbb E}_{\mu_e}[z_i^2] = 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf+%5Czeta%7D%5Bg_i%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D%5Bz_i%5D+%3D+0+%5Cqquad+%5Cqquad+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf+%5Czeta%7D%5Bg_i%5E2%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D%5Bz_i%5E2%5D+%3D+1+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle \mathop{\mathbb E}_{\mathbf \zeta}[g_j] = \mathop{\mathbb E}_{\mu_e}[z_j] = 0 \qquad \qquad \mathop{\mathbb E}_{\mathbf \zeta}[g_j^2] = \mathop{\mathbb E}_{\mu_e}[z_j^2] = 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf+%5Czeta%7D%5Bg_j%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D%5Bz_j%5D+%3D+0+%5Cqquad+%5Cqquad+%09%09%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf+%5Czeta%7D%5Bg_j%5E2%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D%5Bz_j%5E2%5D+%3D+1+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle \qquad \mathop{\mathbb E}_{\mathbf \zeta}[g_i g_j] = \mathop{\mathbb E}_{\mu_e}[z_iz_j] = \langle{\mathbf v_i , \mathbf v_j}\rangle](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cqquad%09%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf+%5Czeta%7D%5Bg_i+g_j%5D+%3D+%09%09%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmu_e%7D%5Bz_iz_j%5D+%3D+%5Clangle%7B%5Cmathbf+v_i+%2C+%5Cmathbf+%09%09v_j%7D%5Crangle+&bg=eeeeee&fg=666666&s=0&c=20201002)
![{[-1,1]^2}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%5E2%7D&bg=eeeeee&fg=000000&s=0&c=20201002)


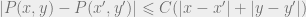



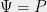
![\mathop{\mathbb E}_{\mathbf{z}^R_{1}, \mathbf{z}^R_2} \Big[ P(H(\mathbf{z}_1^R), H(\mathbf{z}_2^R))\Big] = \mathop{\mathbb E}_{\mathbf{g}^R_{1}, \mathbf{g}^R_2}\Big[ P(H(\mathbf{g}_1^R) , H(\mathbf{g}_2^R))\Big] \pm \tau^{O(\epsilon)}](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bz%7D%5ER_%7B1%7D%2C+%5Cmathbf%7Bz%7D%5ER_2%7D+%5CBig%5B+P%28H%28%5Cmathbf%7Bz%7D_1%5ER%29%2C+H%28%5Cmathbf%7Bz%7D_2%5ER%29%29%5CBig%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7B1%7D%2C+%5Cmathbf%7Bg%7D%5ER_2%7D%5CBig%5B+P%28H%28%5Cmathbf%7Bg%7D_1%5ER%29+%2C+H%28%5Cmathbf%7Bg%7D_2%5ER%29%29%5CBig%5D+%5Cpm+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)
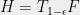







![{\mathop{\mathbb E}[ \xi(H(\mathbf{z}_1^R), H(\mathbf{z}_2^R))] = 0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5B+%5Cxi%28H%28%5Cmathbf%7Bz%7D_1%5ER%29%2C+H%28%5Cmathbf%7Bz%7D_2%5ER%29%29%5D+%3D+0%7D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb E}[\xi(H(\mathbf{g}_1^{n}),H(\mathbf{g}_2^{n}))] \leqslant \mathop{\mathbb E}[\xi(H(\mathbf{z}_1^{n}), H(\mathbf{z}_2^{n}))] + \tau^{O(\epsilon)} = 0 + \tau^{O(\epsilon)} = \tau^{O(\epsilon)} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cxi%28H%28%5Cmathbf%7Bg%7D_1%5E%7Bn%7D%29%2CH%28%5Cmathbf%7Bg%7D_2%5E%7Bn%7D%29%29%5D+%5Cleqslant+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Cxi%28H%28%5Cmathbf%7Bz%7D_1%5E%7Bn%7D%29%2C+H%28%5Cmathbf%7Bz%7D_2%5E%7Bn%7D%29%29%5D+%2B+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+%3D+0+%2B+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+%3D+%5Ctau%5E%7BO%28%5Cepsilon%29%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle \Big|\mathop{\mathbb{E}}_{\mathbf{g}^{R}_1, \mathbf{g}^{R}_2}\big[ P(H^{*}(\mathbf{g}_1^R), H^{*}(\mathbf{g}_2^R))\big] - \mathop{\mathbb{E}}_{\mathbf{g}^R_{1},\mathbf{g}^R_2}\big[P(H(\mathbf{g}_1^R),H(\mathbf{g}_2^R))\big]\Big|](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CBig%7C%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bg%7D%5E%7BR%7D_1%2C+%5Cmathbf%7Bg%7D%5E%7BR%7D_2%7D%5Cbig%5B+P%28H%5E%7B%2A%7D%28%5Cmathbf%7Bg%7D_1%5ER%29%2C+H%5E%7B%2A%7D%28%5Cmathbf%7Bg%7D_2%5ER%29%29%5Cbig%5D+-+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7B1%7D%2C%5Cmathbf%7Bg%7D%5ER_2%7D%5Cbig%5BP%28H%28%5Cmathbf%7Bg%7D_1%5ER%29%2CH%28%5Cmathbf%7Bg%7D_2%5ER%29%29%5Cbig%5D%5CBig%7C+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle \leqslant C\mathop{\mathbb{E}}_{\mathbf{g}^{R}_1,\mathbf{g}^{R}_2}\Big[\big|H^{*}(\mathbf{g}_1^R)-H(\mathbf{g}_1^R)\big|+\big|H^{*}(\mathbf{g}_2^R)-H(\mathbf{g}_2^R)\big|\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleqslant+C%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bg%7D%5E%7BR%7D_1%2C%5Cmathbf%7Bg%7D%5E%7BR%7D_2%7D%5CBig%5B%5Cbig%7CH%5E%7B%2A%7D%28%5Cmathbf%7Bg%7D_1%5ER%29-H%28%5Cmathbf%7Bg%7D_1%5ER%29%5Cbig%7C%2B%5Cbig%7CH%5E%7B%2A%7D%28%5Cmathbf%7Bg%7D_2%5ER%29-H%28%5Cmathbf%7Bg%7D_2%5ER%29%5Cbig%7C%5CBig%5D&bg=eeeeee&fg=000000&s=0&c=20201002)
![\displaystyle\leqslant C\Big( 2 \mathop{\mathbb{E}}_{\mathbf{g}^R_{1},\mathbf{g}^R_2}\Big[ \big|H^*(\mathbf{g}_1^R)-H(\mathbf{g}_1^R)\big|^2+\big|H^*(\mathbf{g}_2^R)-H(\mathbf{g}_2^R)\big|^2\Big]\Big)^{\frac{1}{2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleqslant+C%5CBig%28+2+%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7B1%7D%2C%5Cmathbf%7Bg%7D%5ER_2%7D%5CBig%5B+%5Cbig%7CH%5E%2A%28%5Cmathbf%7Bg%7D_1%5ER%29-H%28%5Cmathbf%7Bg%7D_1%5ER%29%5Cbig%7C%5E2%2B%5Cbig%7CH%5E%2A%28%5Cmathbf%7Bg%7D_2%5ER%29-H%28%5Cmathbf%7Bg%7D_2%5ER%29%5Cbig%7C%5E2%5CBig%5D%5CBig%29%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
![\displaystyle\leqslant C\Big(2\mathop{\mathbb{E}}_{\mathbf{g}^R_{1},\mathbf{g}^R_2}\Big[\xi(H({\mathbf{g}}_1^R),H({\mathbf{g}}_2^R))\Big]\Big)^{\frac{1}{2}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cleqslant+C%5CBig%282%5Cmathop%7B%5Cmathbb%7BE%7D%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7B1%7D%2C%5Cmathbf%7Bg%7D%5ER_2%7D%5CBig%5B%5Cxi%28H%28%7B%5Cmathbf%7Bg%7D%7D_1%5ER%29%2CH%28%7B%5Cmathbf%7Bg%7D%7D_2%5ER%29%29%5CBig%5D%5CBig%29%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D&bg=eeeeee&fg=000000&s=0&c=20201002)



for the GW SDP relaxation of the graph
of the same dimension as the SDP solution
for all
as
where
, the value
and
with the remaining probability.
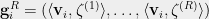
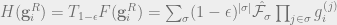
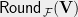
![\displaystyle \mathsf{Round}_{\mathcal{F}}(\mathbf V) = \frac{1}{2}\mathop{\mathbb E}_{e=(v_i,v_j)} \mathop{\mathbb E}_{\mathbf{g}^R_{i}, \mathbf{g}^R_j} \Big[ 1 - H^*({\mathbf{g}}_i^{R}) \cdot H^*({\mathbf{g}}_j^R)\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathsf%7BRound%7D_%7B%5Cmathcal%7BF%7D%7D%28%5Cmathbf+V%29+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathop%7B%5Cmathbb+E%7D_%7Be%3D%28v_i%2Cv_j%29%7D+%5Cmathop%7B%5Cmathbb+E%7D_%7B%5Cmathbf%7Bg%7D%5ER_%7Bi%7D%2C+%5Cmathbf%7Bg%7D%5ER_j%7D+%5CBig%5B+1+-+H%5E%2A%28%7B%5Cmathbf%7Bg%7D%7D_i%5E%7BR%7D%29+%5Ccdot+H%5E%2A%28%7B%5Cmathbf%7Bg%7D%7D_j%5ER%29%5CBig%5D+&bg=eeeeee&fg=000000&s=0&c=20201002)
,
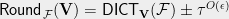

What’s f_{[-1,1]} supposed to be in part 2 of the statement of Theorem 2?
Thanks! the definition of f_{[-1,1]} has been moved up from its earlier position to appear before Theorem 2.
f_{[-1,1]} is a function that is identity on the interval [-1,1] and truncates anything outside the interval to either -1 or 1 depending on its sign.